Early in 2021, a large financial services company approached Aquaforest with the requirement to OCR a large number of legacy documents in a variety of business directories. Once OCR-ed, the company wanted to guarantee that all directory content stays and remains fully text-searchable.
The company had recently migrated all documents concerned to an Office 365 environment and was seeking to execute the initial OCR process as well the subsequent directory monitoring as a ‘Software as a Service’ (SaaS) model.
Aquaforest’s Searchlight product has, for many years, executed tasks like the one described above but was historically sold as a software product installed either on client premises or within a client cloud environment as described in this blog.
To meet customer demand, Aquaforest has now created a new SaaS version of utilising Searchlight’s many features in a cloud environment. We therefore thought it would be a good idea to give you a short overview of how Aquaforest Searchlight as a SaaS works and what helpful steps you can take to find the right dimensioning and conversion speed to suit your requirements.
Early in 2021, a large financial services company approached Aquaforest with the requirement to OCR a large number of legacy documents in a variety of business directories. Once OCR-ed, the company wanted to guarantee that all directory content stays and remains fully text-searchable.
The company had recently migrated all documents concerned to an Office 365 environment and was seeking to execute the initial OCR process as well the subsequent directory monitoring as a ‘Software as a Service’ (SaaS) model.
Aquaforest’s Searchlight product has, for many years, executed tasks like the one described above but was historically sold as a software product installed either on client premises or within a client cloud environment as described in this blog.
To meet customer demand, Aquaforest has now created a new SaaS version of utilising Searchlight’s many features in a cloud environment. We therefore thought it would be a good idea to give you a short overview of how Aquaforest Searchlight as a SaaS works and what helpful steps you can take to find the right dimensioning and conversion speed to suit your requirements.
How is Searchlight hosted?
Aquaforest Searchlight is hosted on a Virtual Machine (VM) in Microsoft’s Azure cloud. All technical spec details such as number of CPU cores, RAM, Premium Disk capability etc. can be selected flexibly to suit the expected workload of your job. Importantly, these can be scaled up or down easily, for example after an initial high-capacity bulk OCR process to a lesser spec for the subsequent permanent monitoring process. In the example of the financial services company, we are using an Azure D8s_v3 sized VM for the initial process. This machine operates Aquaforest Searchlight with 8 cores meaning that eight documents can be OCR-ed or audited in parallel. The VM features 32GB RAM (well above our recommended minimum of 2GB RAM per CPU core).Onboarding – what do you need to consider?
To help us choose the optimal size for your Azure VM appropriately and select the best fitting Aquaforest Searchlight license in terms of CPU cores, we need your input with the following two major parameters:- the total volume of documents (ideally with a rough estimate of the average page count per document) and
- your expected timeframe for the initial conversion of not fully text searchable directories to fully searchable ones
How to find the number of pages in a directory?
It is important to remember that OCR processes are based around the number of pages rather than documents. Aquaforest Searchlight looks at each document and checks each page individually for its searchability. Therefore, to do any meaningful capacity planning, we need to establish or at least estimate the number of pages in a directory rather than using just the number of documents. An easy way of doing this, is to use a free trial version of Aquaforest Searchlight which allows for unlimited Audits on your sites and directories. Download your free trial here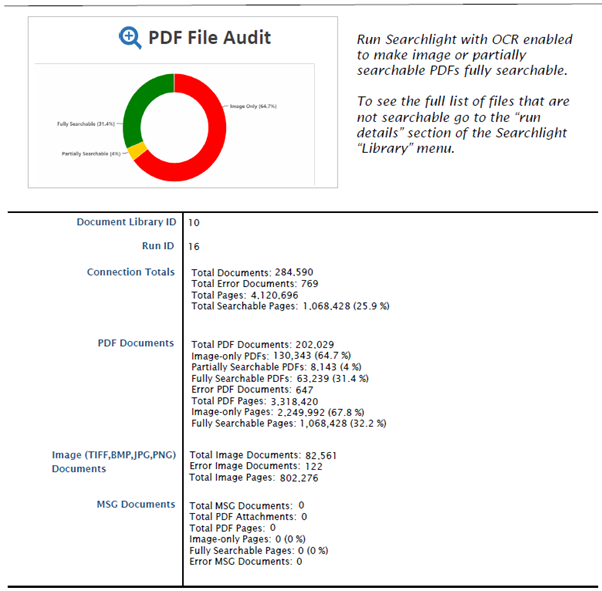
Calculating approximate OCR processing time
Once we have established or estimated the total number of pages to be OCR-ed, we need to look at the time frame available for the job to establish the number CPU cores / VMs required, their size and the corresponding Aquaforest Searchlight licenses.
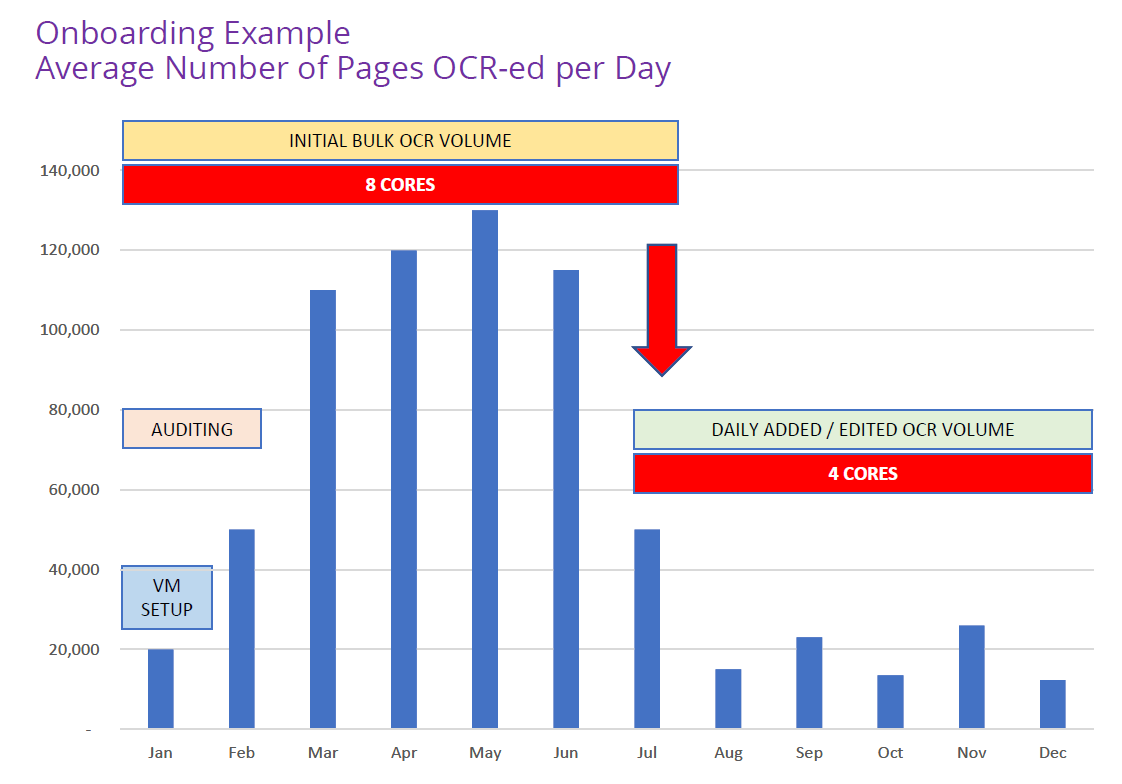
In the example of the financial services company, we arrived at a total of over 5.2 million documents with an average of 20 pages each, therefore a total of more than 104 million pages to be OCR-ed. Based on three trial directories processed and given the average mix of image-only, already fully searchable, and partially searchable pages, we had established an average of 20,000 pages being OCR processed every hour by the 8 core Searchlight application. We then have to divide the 104 million pages by the hourly speed of 20,000 which leads to 5,200 hours or the equivalent of approximately 31 weeks of total OCR-ing time. It was at that point when the true size of the content contained in all these repositories became clear.
Resizing the Searchlight VM after initial OCR
After the initial OCR process is complete, Aquaforest Searchlight will (depending on your settings) monitor all selected directories to ensure that any added or edited content remains fully searchable. If needed, ‘new arrivals’ will be OCR-ed.
At that stage, already fully text-searchable documents are excluded from the OCR process and thus the overall workload for Searchlight will reduce significantly. It is at that point (in our example case roughly after seven months) when it makes sense to downsize both the spec of the Azure VM as well as the Aquaforest Searchlight license. In the case of the financial services company, the license will be reduced from 8 cores to just one core for the monitoring period.
By scaling both the VM size and adapting the Searchlight licenses flexibly in line with that, Aquaforest has created a very adaptable and commercially competitive model to utilise Searchlight’s OCR capabilities in a SaaS environment.