
On first encounter it can be difficult to differentiate between Searchlight and PDF Connector. They both OCR image PDFs (PDFs where the majority of the information is an image of text rather than actual electronically searchable text) to produce searchable PDFs. The following Searchlight vs PDF Connector comparison will cover the fundamental differences.
The Products
Searchlight
Searchlight is an in-place OCR application and can OCR files found on the file system, SharePoint (on-premises and online) and Azure.
It maintains a database of the files it has processed so it does not open the files on subsequent runs (it traverses the storage to identify new or altered files).
It OCRs PDFs and image files (TIFFs, JPEGs, PNGs and BMPs). For the image formats, it creates a new PDF with the same filename.
Our base processing claim is 1000 pages per hour per core, this is dependent on hardware, connectivity and SharePoint throttling.
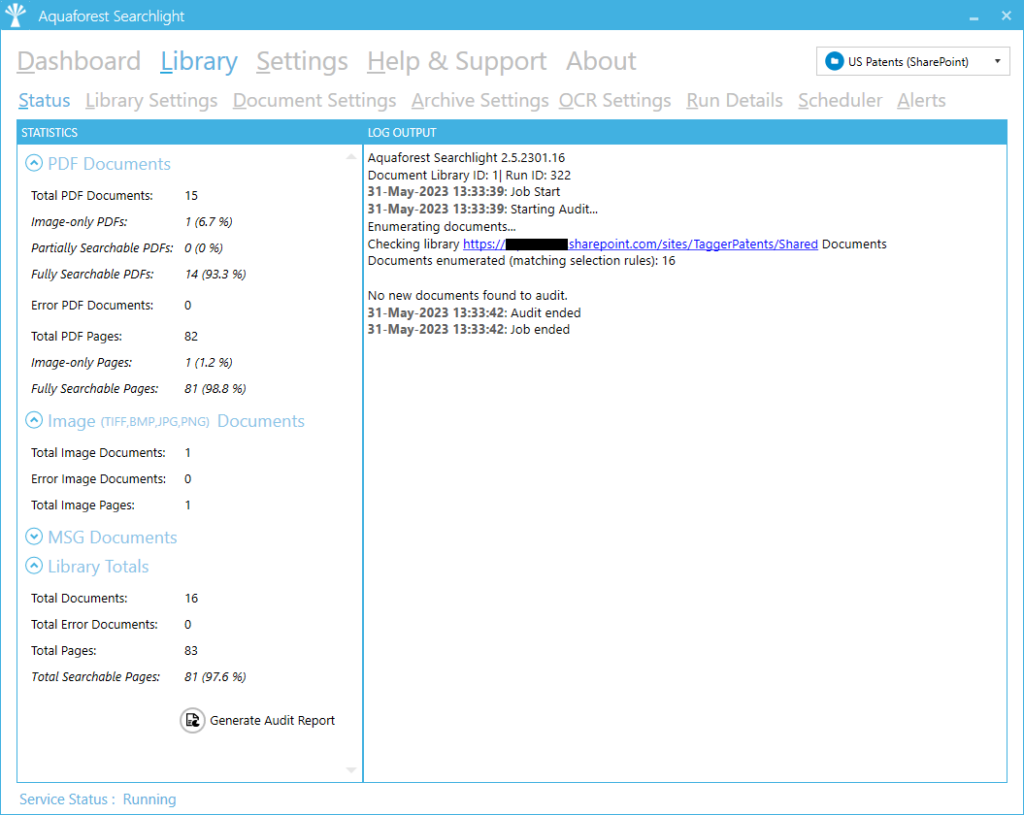
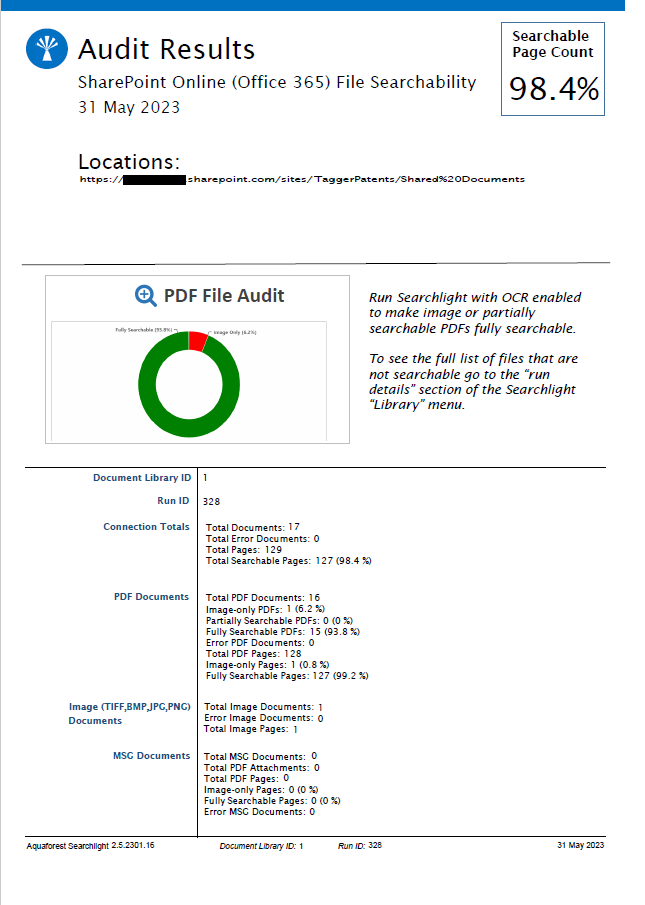
Searchlight offers built-in reporting and a very informative audit report showing the number of image, partially searchable, searchable and error PDFs.
We do offer Searchlight (365) as a SaaS product where we manage the (virtual) server for you.
PDF Connector
PDF Connector is a set of Connectors leveraging the Aquaforest SDK tools in the Power Automate Low-Code space.
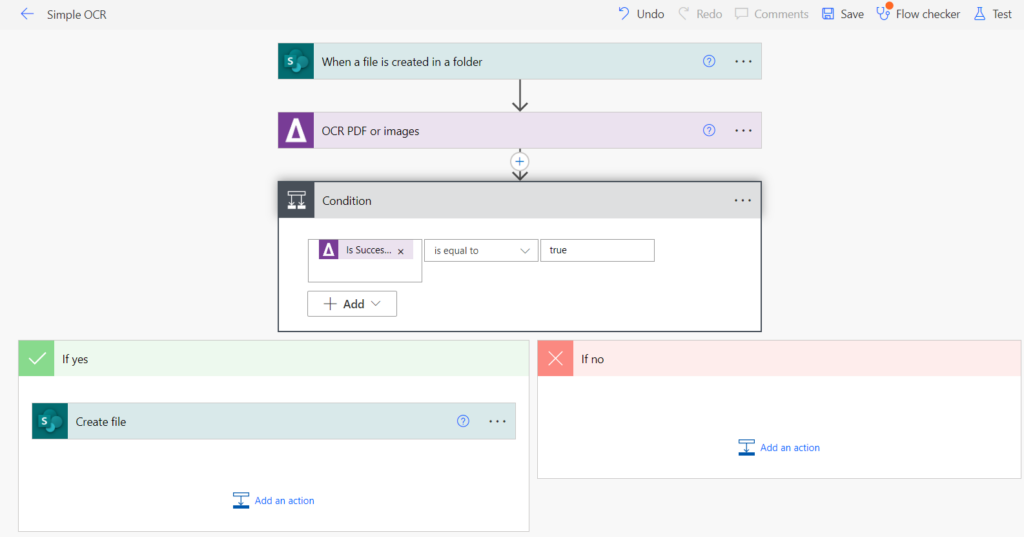
Though a Low-Code solution, it does require some technical knowledge in setting up flows.
There are Power Automate add-ons that allow access to file system files, but the main use is either SharePoint Online or Azure (other connectors such as email are available).
Aquaforest provides a PDF OCR connector.
PDF Connector has a number of connectors beyond just OCR.
In-Place vs Workflow
In-place
Searchlight is an In-Place OCR solution.
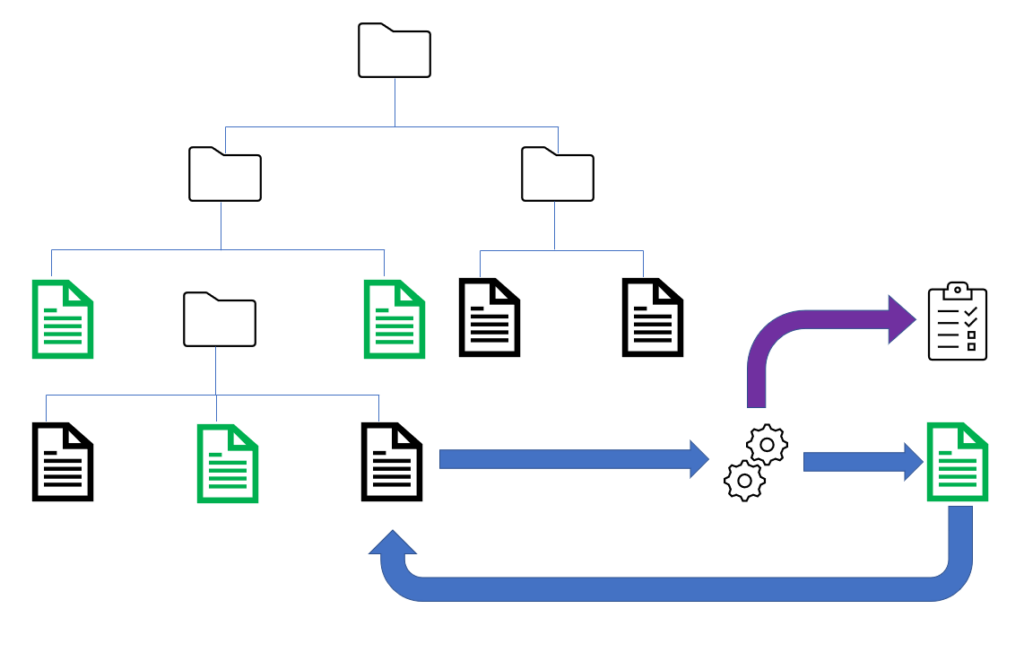
Searchlight will work its way through a file system, SharePoint or Azure storage. Searchlight audits and (if required) OCRs the files – leaving the searchable PDF files in the original location.
A database tracks files processed, so unchanged files are only examined once. If a file is changed, it will be checked, and if required, OCRed.
Workflow
Workflow has an input hopper and an output hopper.
Files are placed in the input hopper (file folder, email folder, SharePoint or Azure location). One or more operations are performed on the file contents and the results are placed in the output hopper. OCR may be one of many intermediate steps.
OCR Engines
Searchlight
Searchlight offers two different OCR engines.
- Aquaforest OCR engine. This supports 23 (Latin character set) languages.
- Canon Iris OCR engine (as also used by Adobe). This supports 131 languages including non-Latin character sets.
Why offer two engines? There are files (especially those with very large pages – for example architectural plans and technical drawings) where the Canon Iris engine struggles and the Aquaforest engine is the only option.
PDF Connector
PDF Connector only offers the Aquaforest OCR engine, supporting 23 (Latin character set) languages.
Hosting
Searchlight
Searchlight is an application running on a real or virtual Microsoft server platform.
This means that you can control where data is processed, though with the additional overhead of maintaining the system.
We do offer a Software as a Service (SaaS) solution (Searchlight 365) where we supply, set up and maintain the virtual machine.
PDF Connector
PDF Connector is entirely hosted by Microsoft, there is no need to worry about hardware or software.
Everything takes place on Microsoft virtual hardware, though you can define which region is hosting it (probably the one nearest your SharePoint store is your best option).
