
One of the appeals of SharePoint is ability for multiple users to create, upload and modify documents in document libraries, often spanning across several SharePoint farms. The visibility of those documents is a key aspect of a well-managed SharePoint environment. However, as the complexity and volume of data stored increases, managing such environments can become quite challenging.
One scenario that is very likely to happen over time is different users uploading the same document to numerous document libraries, thus creating lots of duplicate documents. Keeping track of duplicate documents spread across multiple farms can be extremely problematic.
Duplicates in SharePoint
To identify duplicate documents in SharePoint (2013), you need to turn on the Show View Duplicates link in the search results web part settings in the Search Center.
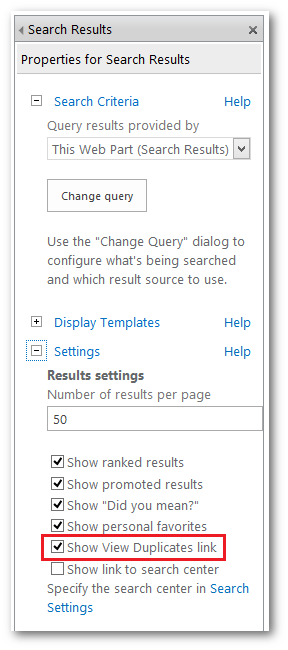
If duplicate documents are found, the VIEW DUPLICATES link is shown in the preview pane:
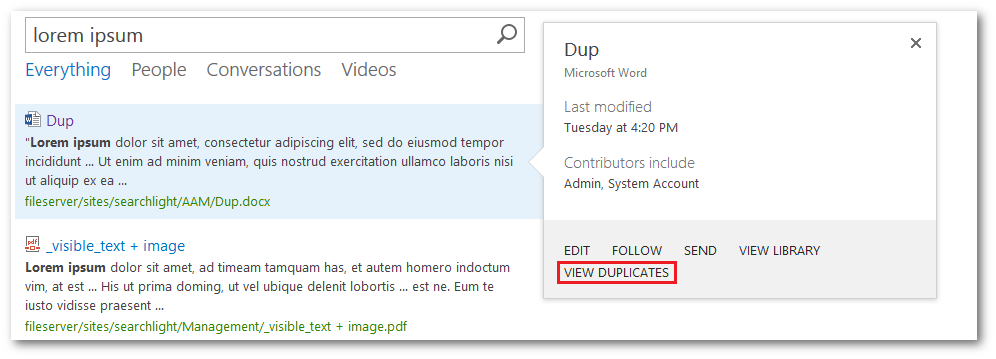
Clicking on the VIEW DUPLICATES link will display all the duplicate results.
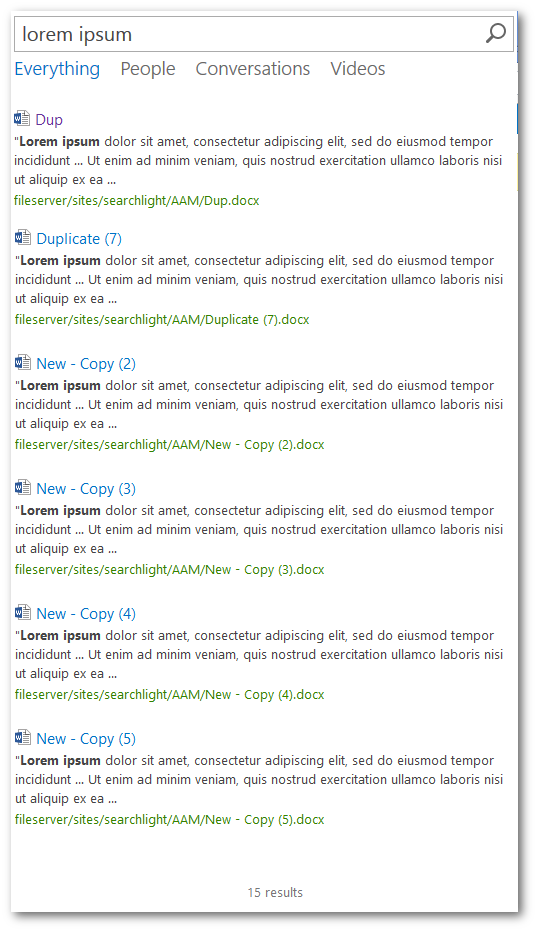
What makes a document duplicate in SharePoint?
Duplicate documents identification has evolved in the different versions of SharePoint but the underlying principle is still the same – it uses a technique called shingling. Basically, it is a method of hashing documents as they are indexed in SharePoint. Each document is broken down in same sized chunks and hashed. When hashing documents, only the document content (no filenames, no metadata, no URLs, etc.) is used. These hashes are stored in the search database for each document in the search index (source). In SharePoint 2007, these hashes were stored in MSSDuplicateHashes tables in the search database whereas in SharePoint 2013 these hashes are stored in the DocumentSignature managed property as documented here.
When a query is performed and View Duplicates is set to true, the hashes in the search database is compared with the hashes of the main result set. If there are any matching hashes, they are regarded as duplicates or more accurately as near-duplicates (near-duplicates and shingling is explained more comprehensively here).
To illustrate this lets upload 5 documents to a document library.
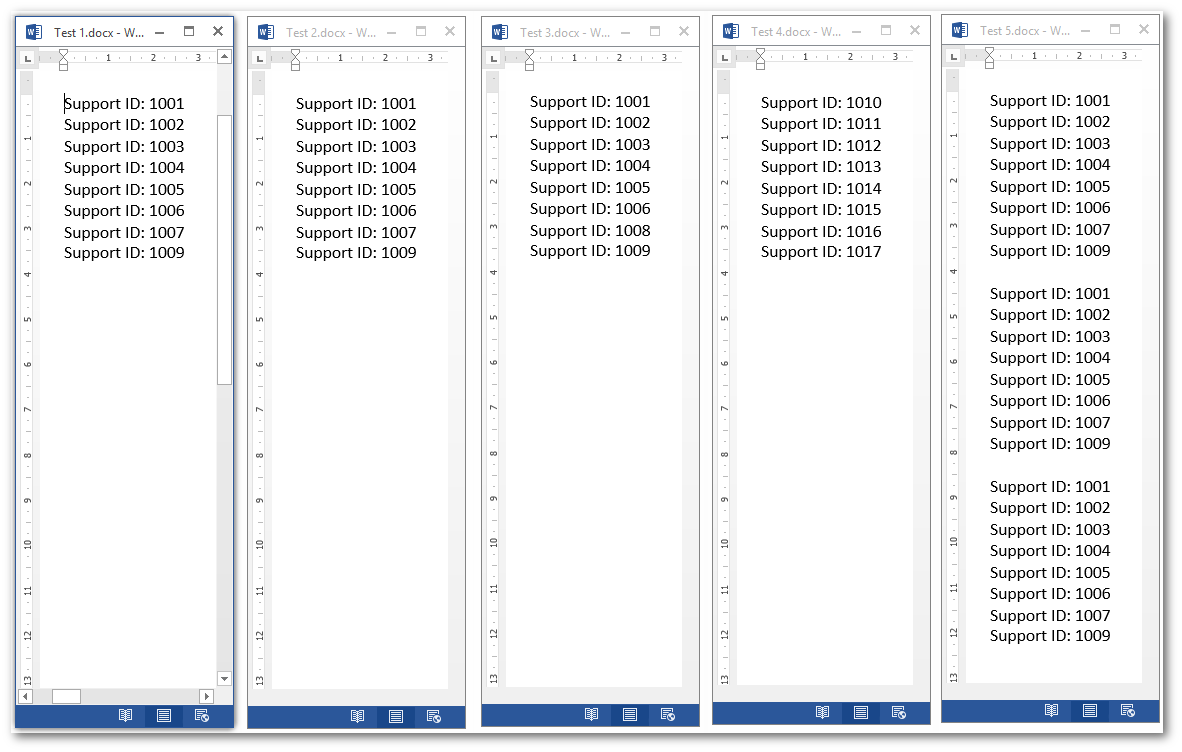
Test 1.docx and Test 2.docx are identical whereas Test 5.docx has the contents of Test 1.docx and Test 2.docx 3 times.
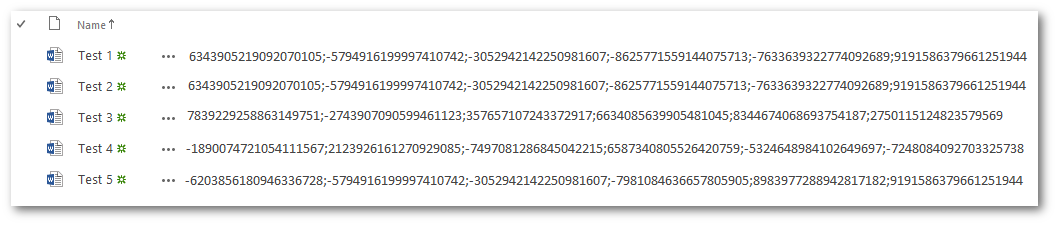
Below are the DocumentSignature of each document after they have been indexed by SharePoint:
If we do a search for “Support ID:”, the following 3 results are returned:
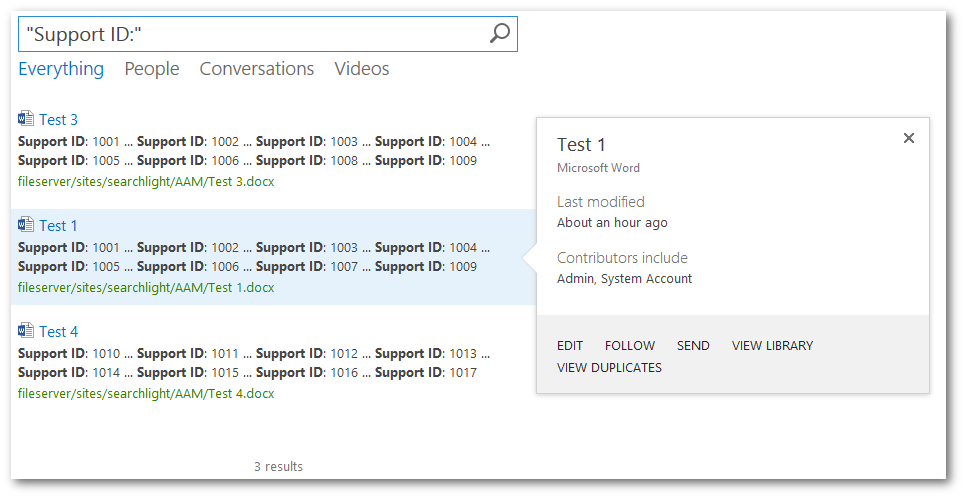
Only, Test 1 has the VIEW DUPLICATES link. If we click on the link, we get all the duplicates of Test 1:
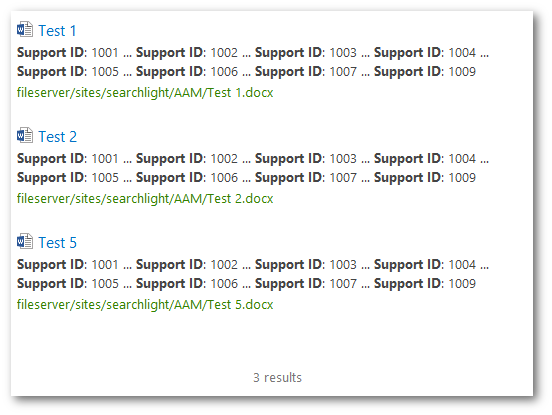
Test 2 was expected to be a duplicate of Test 1 as they both have the exact same text content but the duplicate result set also has Test 5. If we analyse the DocumentSignature of the documents (below), we’ll notice that Test 5 shares 3 hashes with Test 1 and Test 2. This is enough for SharePoint to consider it a duplicate of Test 1 and Test 2, hence why in SharePoint we get near duplicates rather than exact duplicates. The more hashes results have in common, the more identical they will be (Test 1 and Test 2 have identical hashes).

Issues
The fact that SharePoint returns near duplicates instead of exact duplicates can make duplicate documents identification process more cumbersome, as the user will need to open each of those documents and check for differences. For example, if a document library has invoices, it is very likely that all the invoices have the same template (same header, same fields, etc.) but different values.
Presently, you can identify duplicate (near-duplicate) documents only by specifying a query. For instance, if you want to find if a particular document has duplicates, you search for the document name and see if SharePoint returns any duplicates of that document. It might also return other documents with the same name that are not duplicates, which you will need to filter out manually. However, if you want to find all duplicate documents in a site, you cannot do that because there is not a way to retrieve all documents through the SharePoint search interface. The only possibility is to use wildcards such as “a*”, “b*”, “1*” and so on. This is a very tedious and time consuming process.
Also, before SharePoint can return duplicate documents, it has to index the documents first. So, if duplicate documents are added before a crawl has been performed, those new duplicate documents will not be retrieved. While you can force a crawl on SharePoint On-Premise, there is currently no way to force a crawl or modify the crawl interval in SharePoint Online (Office 365).
Alternative/Solution
Aquaforest CheckPoint to the rescue! Apart from helping SharePoint administrators manage different areas of their SharePoint environments, Aquaforest CheckPoint can also help identify duplicate documents. However, our duplicate documents identification process is slightly different from SharePoint’s. In Aquaforest CheckPoint, documents are duplicate if they are the same size and have the same MD5 hash. So, if we wanted to find all duplicate documents in a document library, we just group all files by their size, discard groups with only one entry, download and calculate the MD5 hash of the remaining files. Any matching hashes are considered exact duplicates.
However, this approach does not work for Office documents. This is because the metadata for office documents in SharePoint is stored within the document itself whereas for other document types the metadata is stored in the SharePoint content database. Consequently, if we upload the same office document twice in SharePoint, it can result in the documents being different sizes (usually the difference is around 10 bytes) due to the metadata being added to them. As a result, we can no longer group the documents by size. Even if they end up being the same size, their MD5 hashes will be different.
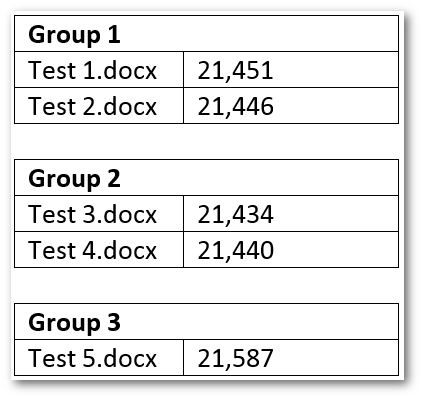
To overcome these issues, we had to first add a size threshold so that we can group documents that have sizes within the threshold limit. For instance, these are the actual sizes of the documents in SharePoint:
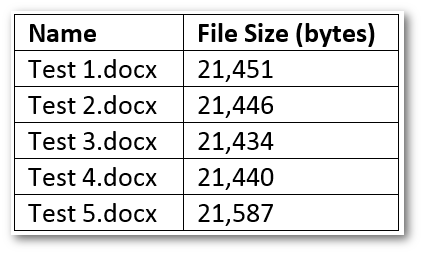
If we were to group them by size (without any size threshold), we would have 5 groups each with one entry and because of only having one entry they would all be discarded. However, if we set a threshold of 10 bytes, that is, group items by size where the size of each document in a group can be +/- 10 bytes, we would have 3 groups:
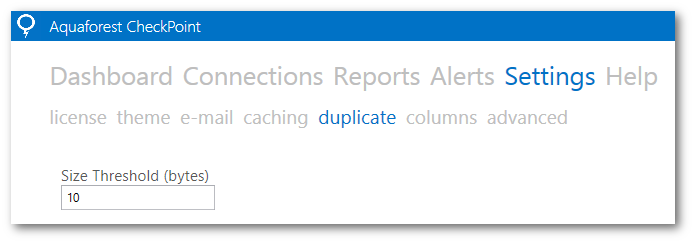
The size threshold limit can be controlled in Settings > Duplicate page in Aquaforest CheckPoint:
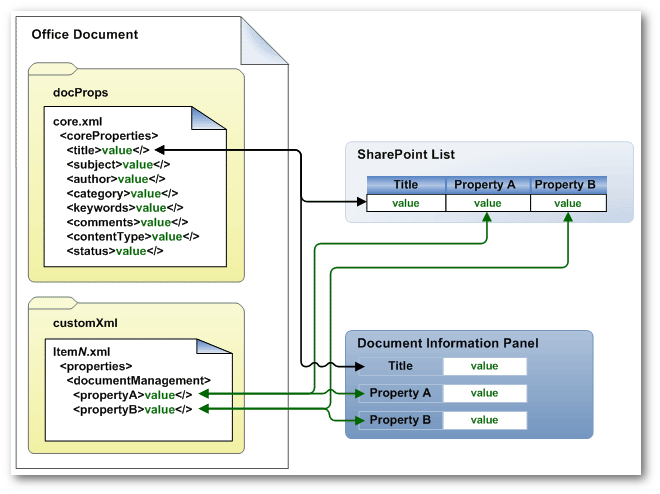
Secondly we have to delete the additional metadata being added by SharePoint from the documents so as not to affect the MD5 hash. In order to do that we have to first understand how the metadata is stored in the documents. As described in this article, “Document properties that are defined in the content type assigned to the document are contained in the customXml section of the Open XML Formats.”
So, to remove the metadata we just need to remove the customXml. As it turns out, we can easily get to the customXml if we unzipped the downloaded office document.

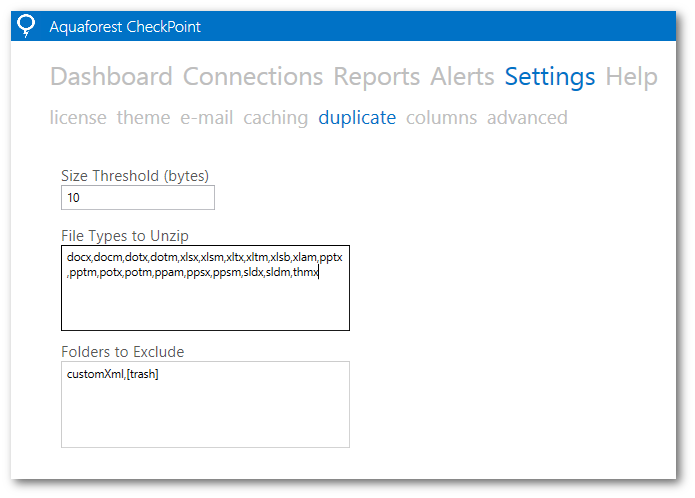
From our tests we found out that deleting the “customXml” and “[trash]” folders and hashing the remaining items enables us to identify duplicate office documents correctly. We can configure which file types to unzip and which folders to delete in Settings > Duplicate page in Aquaforest CheckPoint:
Now if we run the duplicate document report in Aquaforest CheckPoint, we can see the duplicate files identified properly with the same MD5 hash even though the file sizes are different.
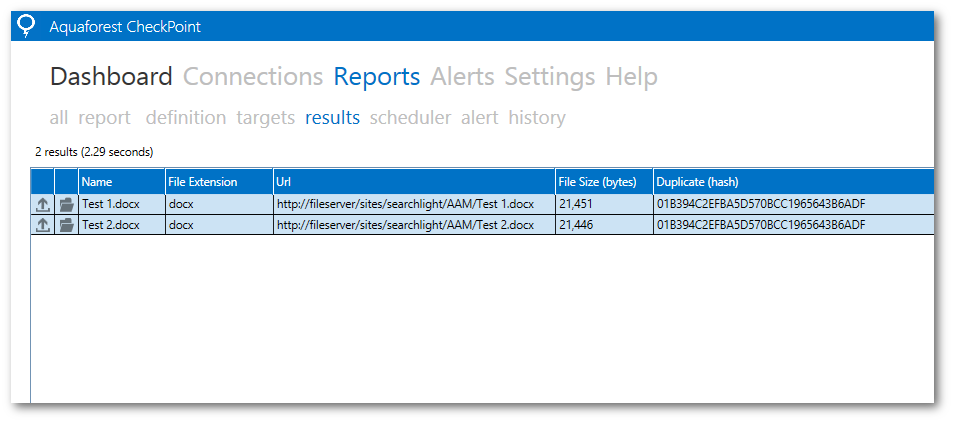
One very nice feature with Aquaforest CheckPoint is that you can identify duplicates across both SharePoint On-Premise and SharePoint Online (Office 365). To illustrate this let’s look at the following example.
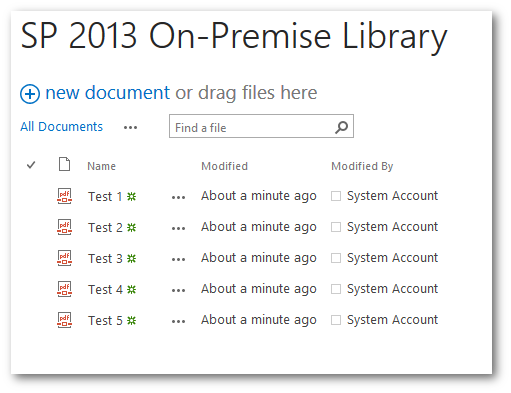
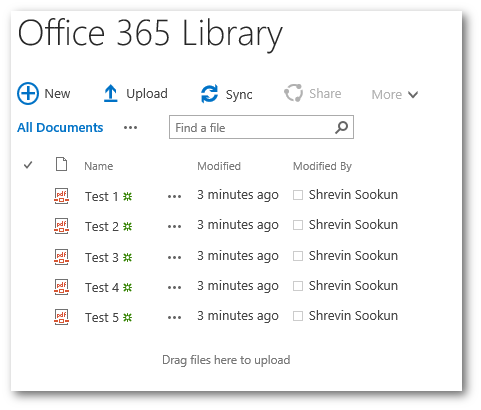
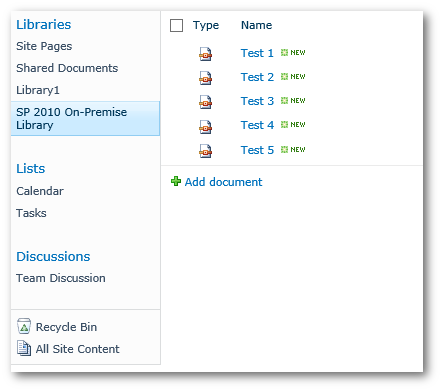
I have uploaded the same 5 PDF documents in a library in Office 365, SharePoint 2013 On-Premise and SharePoint 2010.
 |
 |
 |
Below are the results after running the duplicate report. The duplicates are grouped by hash and colour coded. Note: These documents do not need to be indexed by SharePoint for Aquaforest CheckPoint to indentify the duplicates.
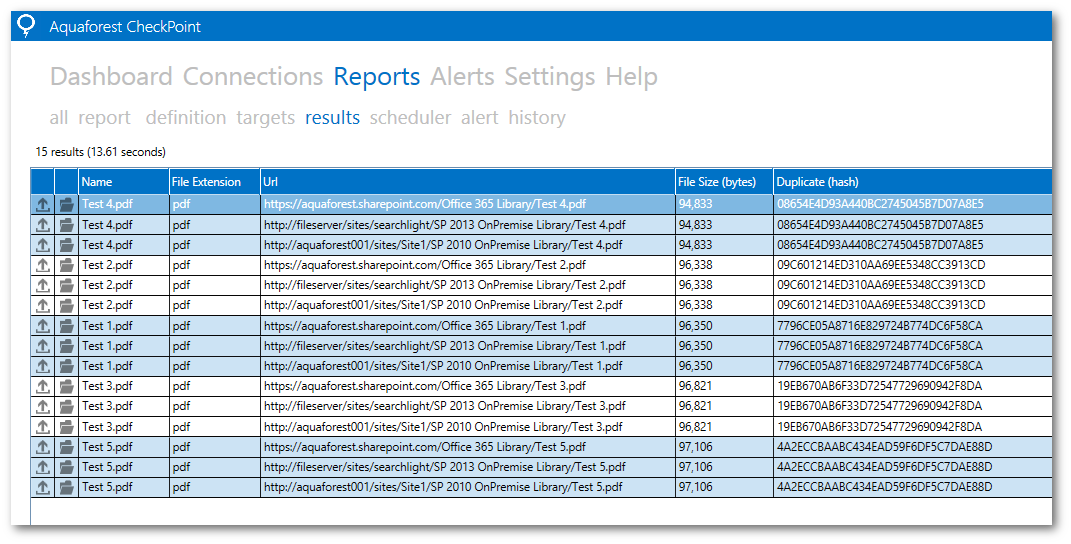
For this to work for office documents, you might need to be slightly more aggressive with the size threshold because the metadata issue described above. In addition to this, you also need to add “docProps” folder from the unzipped contents to the “Folders to Exclude” setting in Aquaforest CheckPoint.
The results returned by Aquaforest CheckPoint after adding the office documents to the SharePoint libraries are shown below.
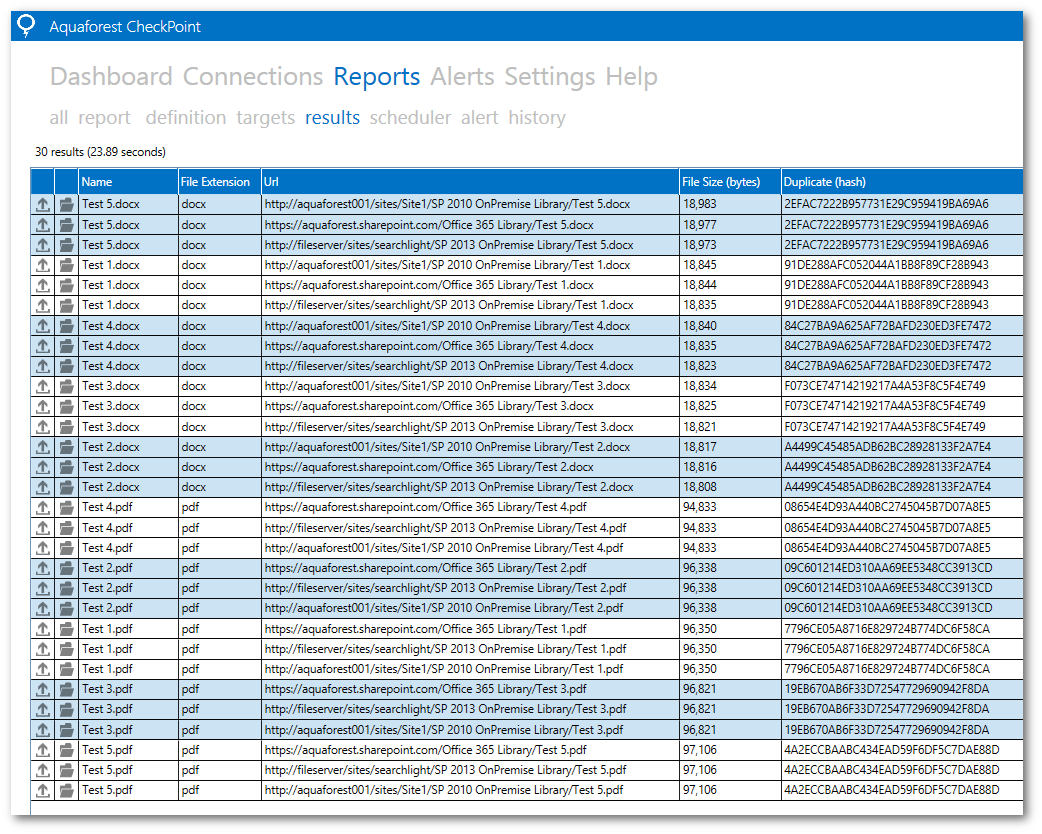
At the time of writing this blog, Aquaforest CheckPoint is only on its first version and the current limitation is that the duplicate document detection only works for document libraries. It will not work for finding duplicate document attachments in list items.
References:
- https://msdn.microsoft.com/en-us/library/jj687488.aspx
- http://blogs.technet.com/b/fesiro/archive/2013/11/11/sharepoint-2013-search-near-duplicates-and-documentsignature.aspx
- http://blogs.technet.com/b/jpradeep/archive/2010/09/29/moss-2007-duplicate-search-results.aspx
- http://nlp.stanford.edu/IR-book/html/htmledition/near-duplicates-and-shingling-1.html
- https://searchunleashed.wordpress.com/2011/12/08/how-remove-duplicate-results-works-in-fast-search-for-sharepoint/
- https://msdn.microsoft.com/en-us/library/bb447589.aspx
- http://sadomovalex.blogspot.co.uk/2012/12/remove-sharepoint-metadata-from-ms.html
