
Our no-code OCR server, Autobahn DX, allows users to set up and customize workflows with ease and run them automatically. It also works well when processing large volumes of documents, thanks to an AI-powered OCR engine. The KVP step extracts important information from PDF files in pairs. It effectively extracts key-value pairs (KVPs) from unstructured documents or images. Leveraging AI, ML, and adaptive layout understanding, you can automatically label and extract information such as phone numbers, IBANs, credit cards, names, and email addresses.
The engine can handle scenarios like text recognition in noisy documents, recognition of dotted lines, handling touching and broken characters, text on colored backgrounds, underlined text, skewed text, and text in graphics and tables. Follow this guide to learn how to extract data from PDFs by using intelligent document processing.
1. Create a new job.
Click Create New. Fill in the Source Folder and Destination Folder fields by clicking the magnifying glass to the right of these fields. The source (input) folder is where all the files you want to extract would go. The destination (output) folder will initially be empty, but it’s where all the processed files will end up.
2. Select the Key Value Pair Extraction.
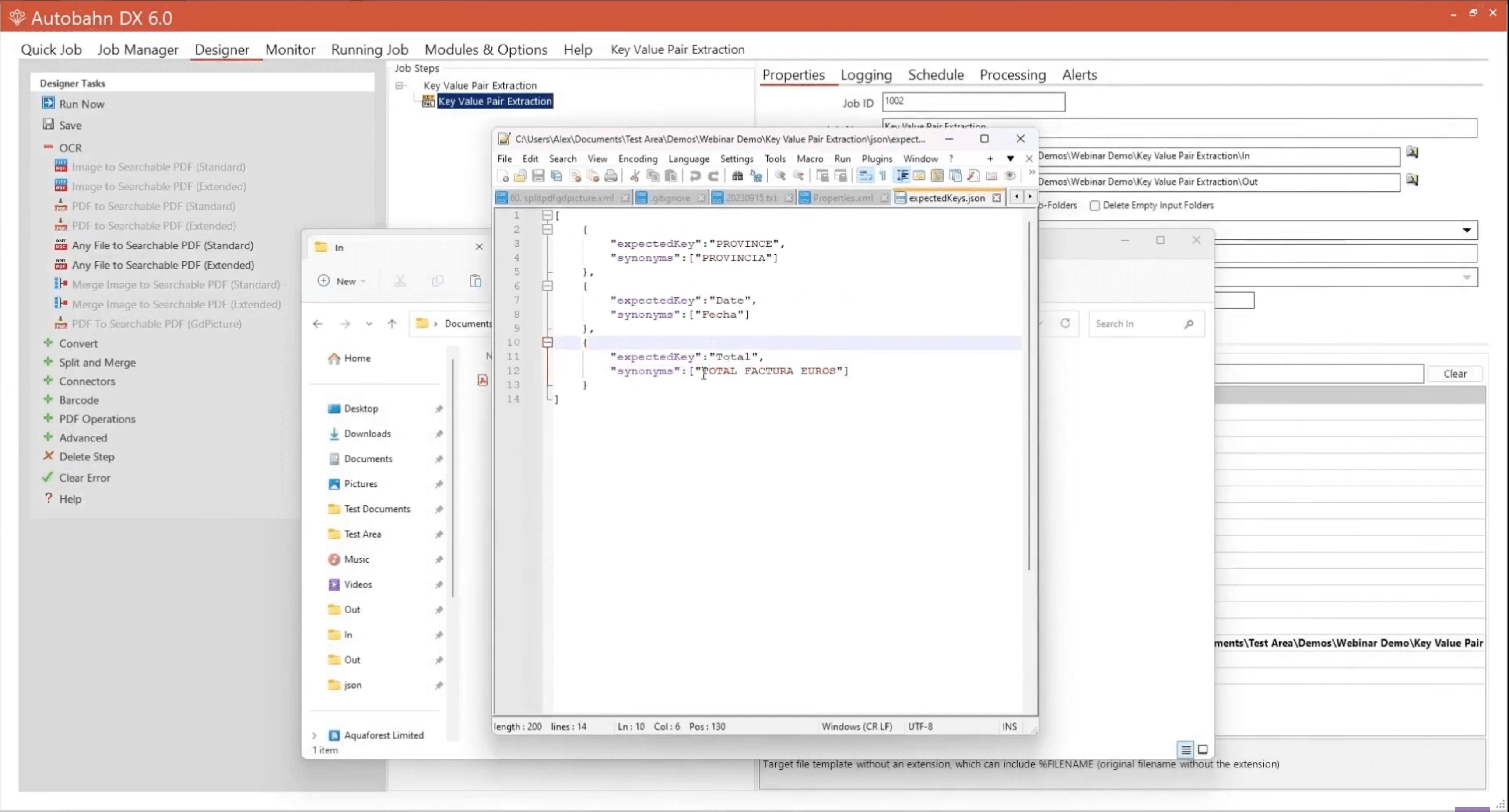
In the left-side navigation, you will find the KVP step in the Advanced menu. For this step, you need to set up the expected keys and the synonym. See the example below.
So if the key-value pair extraction finds this, then it will give a value and output it paired with the total instead.
If you just want to get all the data, then you don’t need to use and expect the keys and there’s more information that you can extract.
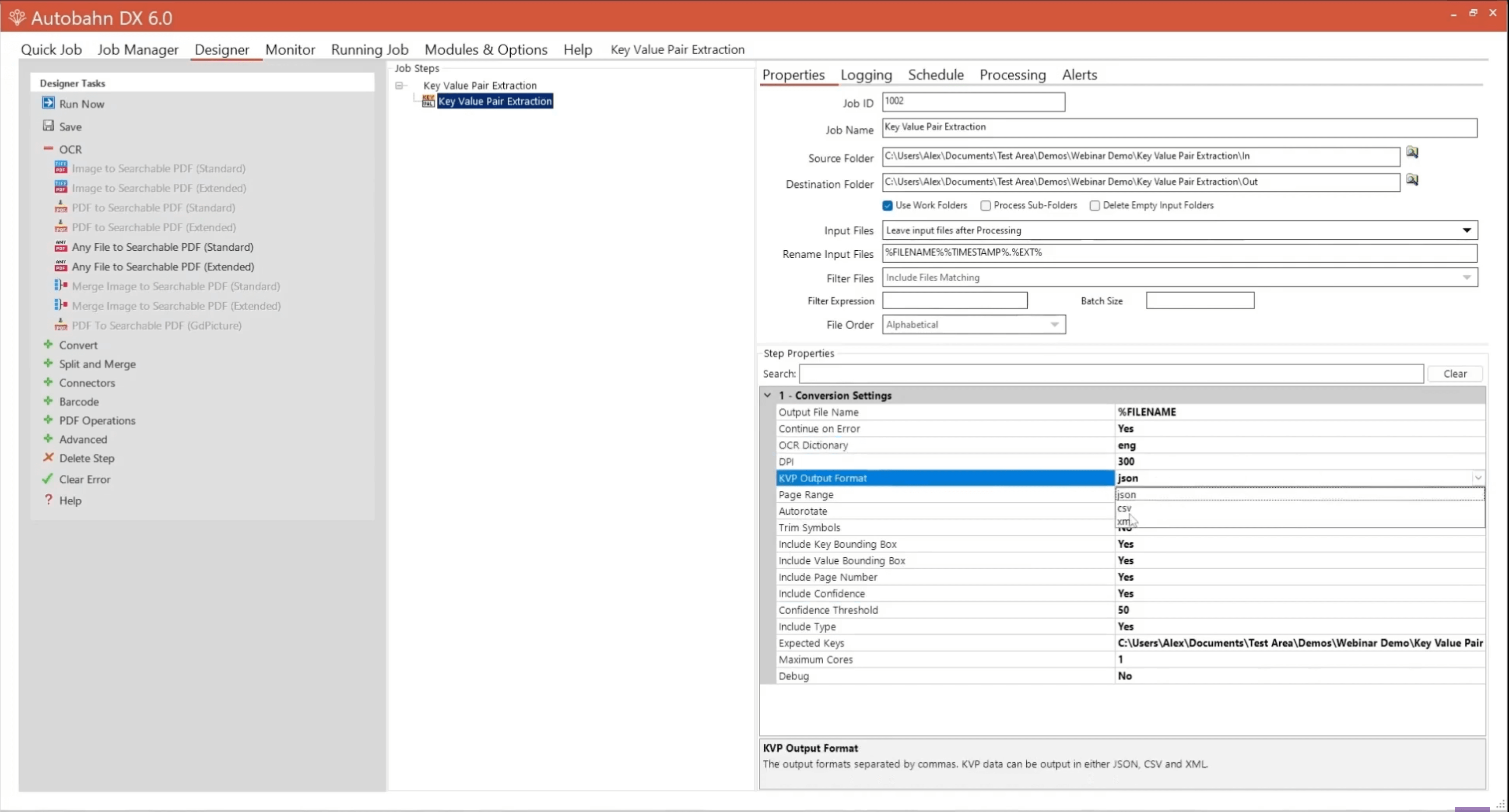
In this example, we set up the JSON as the output, but you can also choose CSV or XML.
If you want to try these steps yourself, download the free trial of Autobahn DX and make your documents searchable. Or, if you prefer to see these steps in action, check out our video tutorial below.
