
Searchlight Tagger is a powerful application, able to extract text from documents in a variety of ways and populate SharePoint columns with the data it has found.
In this article, however, we shall be looking exclusively at managed metadata columns. There will also be a video at the end of this blog going into more detail.
Searchlight Tagger will be used to check a PDF, look for any matches with a pre-defined term store and then populate the column with the found data.
To start, I am going to make a new job in Searchlight Tagger
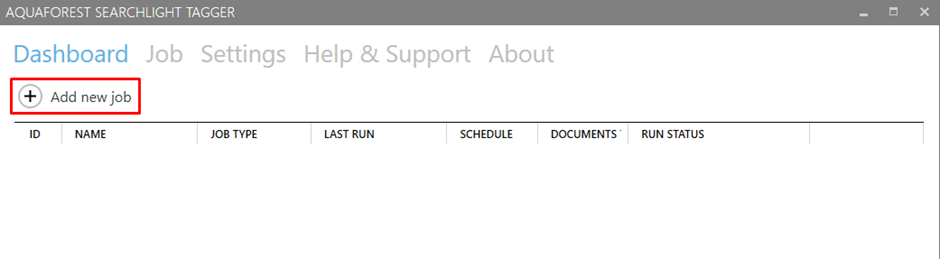
This will take us to the Create New Job Wizard. This will guide us though all of the settings.
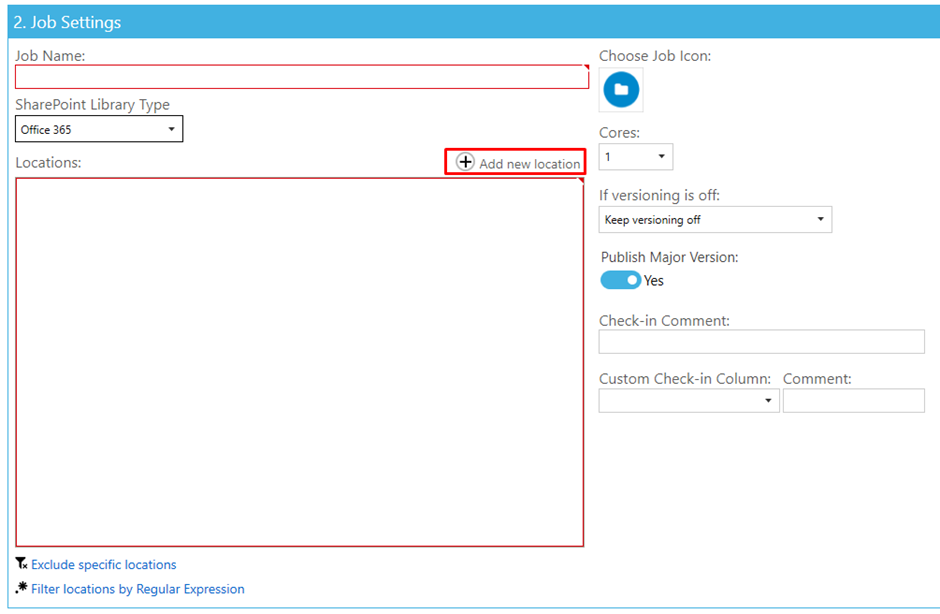
The first part of the job creation is your location settings. Here you can add what libraries and sites Tagger will process.
To start, simply enter a Job Name, select your Library Type and then click “Add new location”.
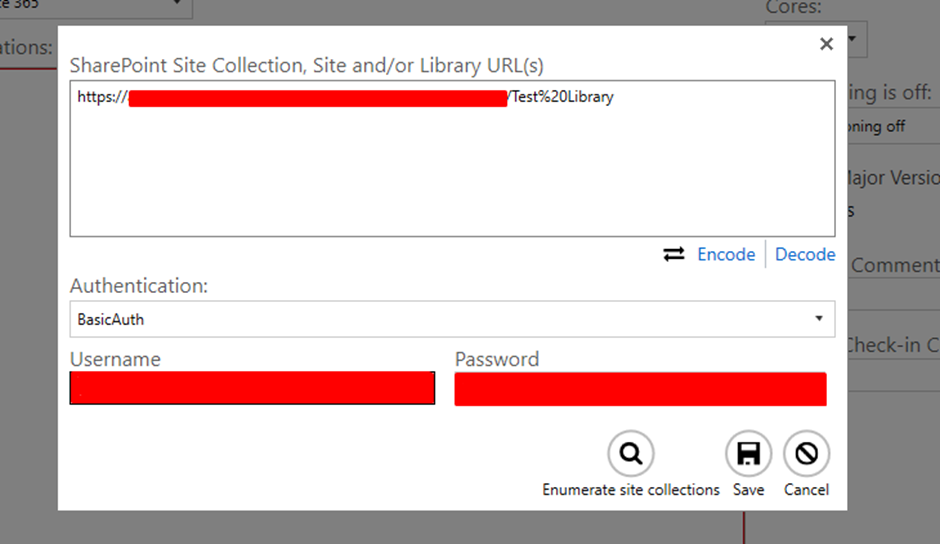
There a selection of authentication methods too, but for this article, I am simply using “Basic Auth”.
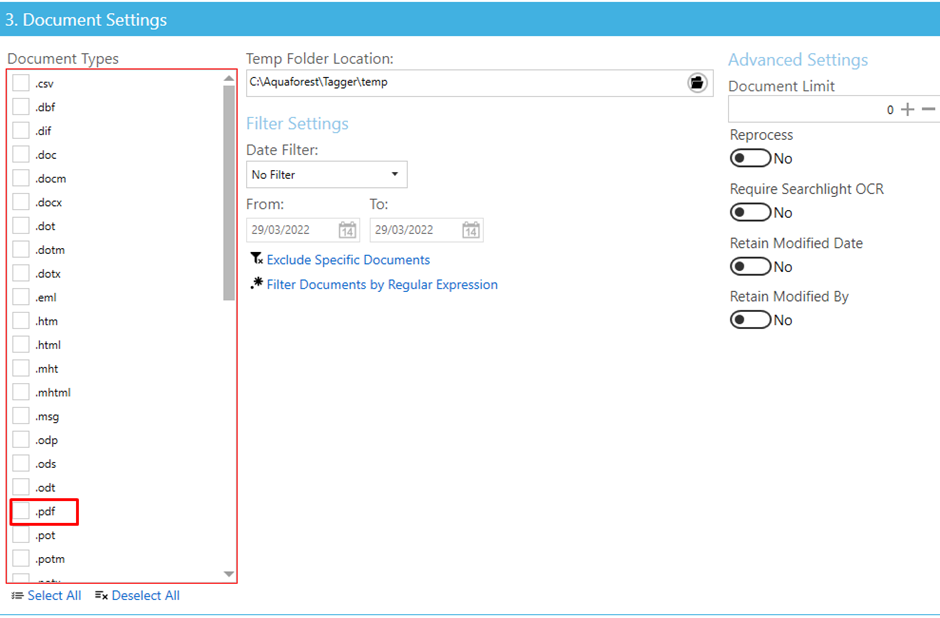
Now that our location is added, it is time to setup the document settings. There are quite a few settings here, but for this blog, all I will be changing is the option to enable “PDF”s to be processed.
Now we are onto the focus of this blog. In the Metadata settings, you will want to go to the “Taxonomy Matching Settings” and enable this setting.
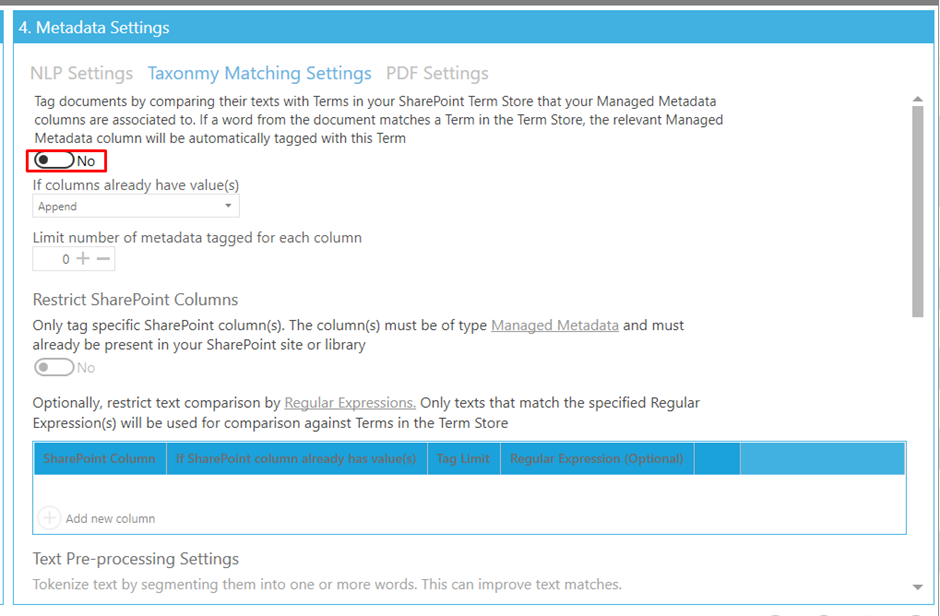
There are more settings here, but I won’t be changing them, in this blog.
The rest of the settings of this job can be left as default.
I am now ready to run. Here is a before screenshot of some sample documents.
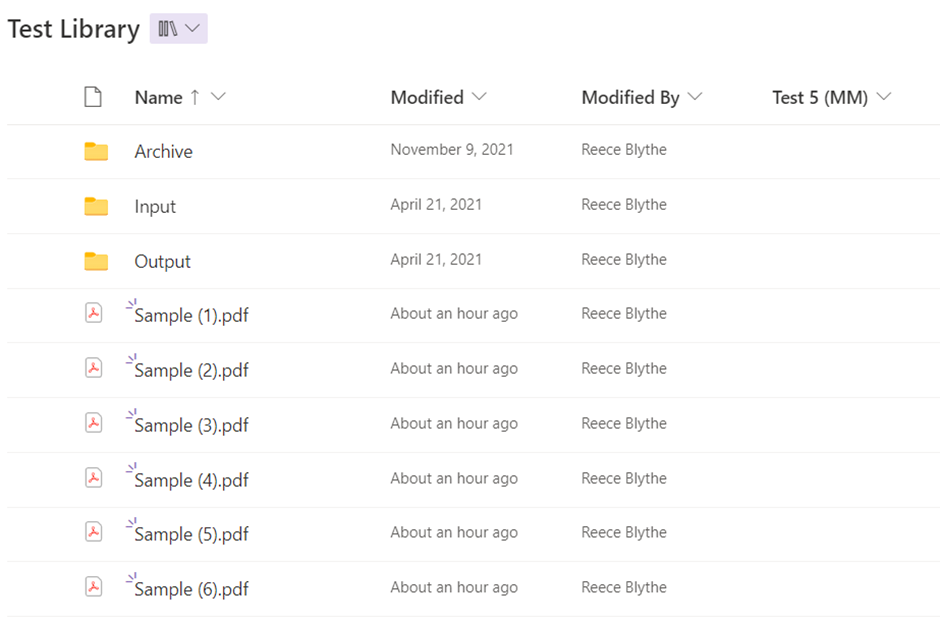
The text I am looking for and that is in my term store for my managed meta data column, “Test 5 (MM)”.
And here is after the job has completed.
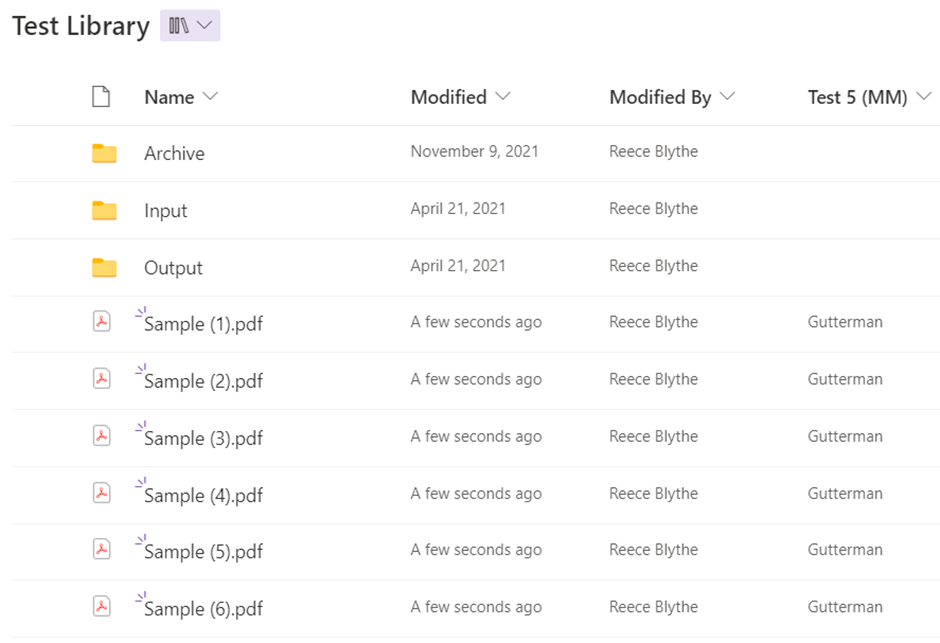
And with that, you are ready to start tagging your own libraries. You can download the free trial of Searchlight Tagger here.
