
Aquaforest PDF Connector User Guide


Getting Started
Create account
First of all, you need to Create an Aquaforest PDF API Account. This account is used to manage Aquaforest PDF Actions and Aquaforest PDF API. Use your active email address, because the subscription will be linked to this address. If you already have an account, just sign in here.
Generate API key
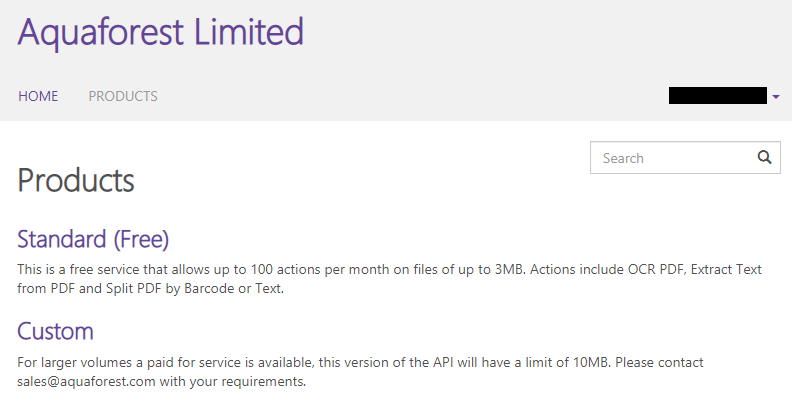
Click the subscribe button.
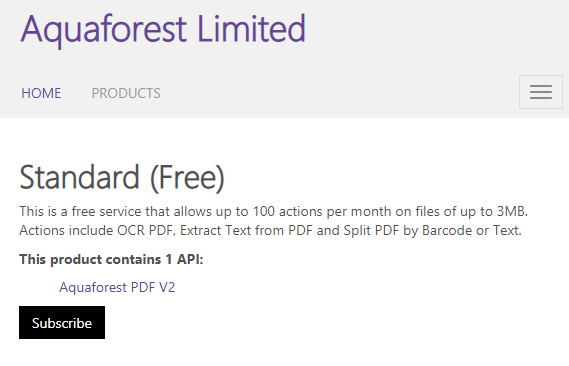
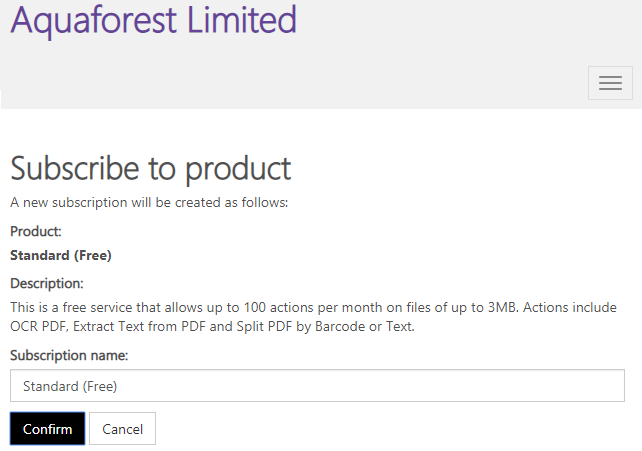
Click the confirm button to confirm your request or the cancel button to cancel the request.
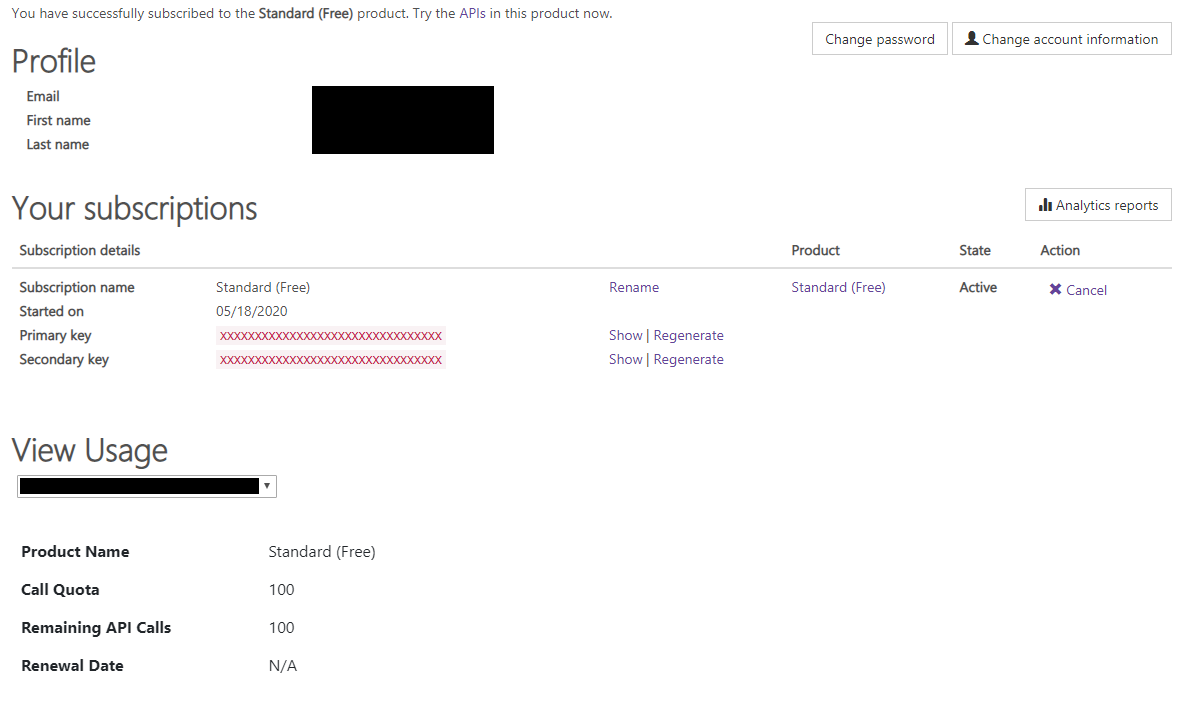
Aquaforest Zonal Extractor Tool
Some actions in the Aquaforest PDF Connector give you the ability to take action dependent upon text or barcodes at a certain location on a page.
The Aquaforest Zonal Extractor tool is used to help you find the coordinates of this location and can be accessed via https://www.aquaforest.com/en/Zonal/ZoneExtraction
Licensing
- 1 unit per page for OCR PDF or images actions
- 1 unit per page for Get data from PDF actions
For all other actions :
- Input files up to 10 pages : 1 unit per input file
- Input files over 10 pages : 1 unit per 10 pages processed
Power Automate
Power Automate Setup
When adding a new action in Power Automate, search for and select Aquaforest PDF connector. This will show you a list of the available Aquaforest Power Automate Actions.
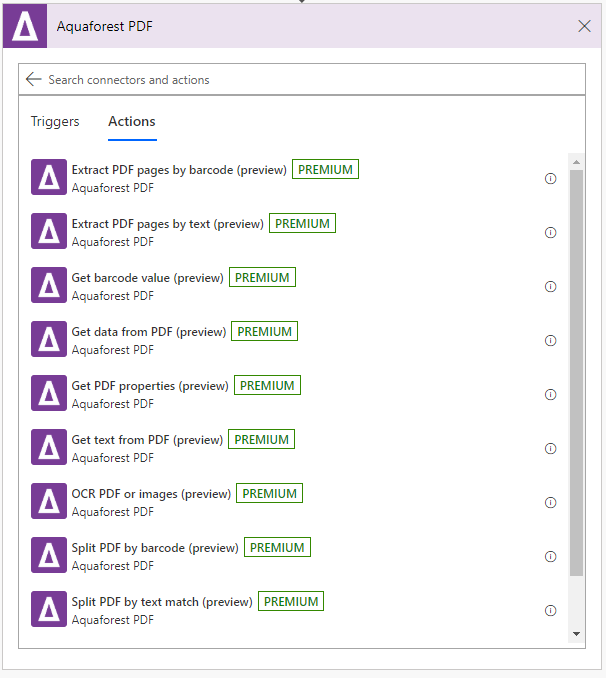
Power Automate Actions
Get data from PDF
This action will extract important data from PDF files in the form of Key/Value pairs.
Input Parameters
Required Parameters
File Content:
Data Type = string (byte – base 64 string)
The content of the source file
Optional Parameters
Expected Keys:
Data Type = string (One key per line)
Provide one key name per line to make values available to later actions without parsing JSON.
Page Limit:
Data Type = integer
Maximum number of pages to be processed
Page Range:
Data Type = string
A string representation of the page numbers you want to process. E.g. 1,3-4
Dates as ISO:
Data Type = boolean
Set this to true if you want the date values to be returned as an ISO Date
Confidence Score:
Data Type = number
Set a higher confidence score to filter out values with lower confidence. The value range is between 0 and 1, and the recommended value for meaningful key/value pairs is 0.5 and above
Strip Currency Symbols:
Data Type = boolean
Set this to true if you want the symbols and strings to be removed before we return currency values
Match Synonym:
Data Type = boolean
Set this to true if you want us to return all the keys that are synonyms to the expected key
Synonym Dictionary:
Data Type = string
You can provide a JSON array of “entry” objects, where each object contains a list of synonyms in an array. For instance, if you want “Invoice No” and “Invoice Number” (case-insensitive) to be interpreted as the same key, use the following JSON: [{‘entry’: [ ‘Invoice No’, ‘invoice number’ ]}]
Trim Symbols:
Data Type = boolean
Set this to true if you want us to remove all leading and trailing symbols from the keys found before we match them to an expected key.
Output Parameters
- LicenseType
- CallsRemaining
- CallsMade
- RenewalDate
Error message: Data Type = string Error message Is Successful: Data Type = boolean This will be true if data was extracted from the file. Pages: Data Type = object[] A list of pages containing Key/Value pairs.
Page Number:
Data Type = integer
The page number of the current page
Page Height:
Data Type = integer
The height of the current page
Page Width:
Data Type = integer
The width of the current page
Page Key/Value Pairs:
Data Type = object[]
A list of Key/Value pairs extracted from a page.
Key:
Data Type = object
Object representing a Key
Key Text:
Data Type = string
String showing the content of the key
Bounding Box:
Data Type = object
A rectangle representing the position of the key on a page.
Top:
Data Type = number
The top coordinate of the bounding box
Left:
Data Type = number
The left coordinate of the bounding box
Height:
Data Type = number
The height of the bounding box
Width:
Data Type = number
The width of the bounding box
Values
Data Type = object[]
Object representing a Value
Value Text:
Data Type = string
String showing the content of the value
Confidence:
Data Type = number
A score of how confident we are that this value matches with the key.
Bounding Box:
Data Type = object
A rectangle representing the position of the Value Text on the page.
Top:
Data Type = number
The top coordinate of the bounding box
Left:
Data Type = number
The left coordinate of the bounding box
Height:
Data Type = number
The height of the bounding box
Width:
Data Type = number
The width of the bounding box
Get text from PDF
Extracts text from a PDF files in a smart way, the extracted information can be used to rename the file in Power Automate, it can also be used as an input to other processes. Properties like the location of the text on the page and regular expressions can be used to fine tune the result.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
Text Result Template:
Data Type = string
Template for the output text result if a text match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
%VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
%VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No Text Match Template:
Data Type = string
Template for the text to be returned if a text match is not found
Optional Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
Text Result Template:
Data Type = string
Template for the output text result if a text match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
%VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
%VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No Text Match Template:
Data Type = string
Template for the text to be returned if a text match is not found
Text Location:
Data Type = string
This represents the coordinates of a rectangle that covers the text you want us to extract. You can use this page to get the coordinates in relation to your input files.
Page (Deprecated):
Data Type = integer
This property is deprecated, we advise you to use the Pages property. The Pages property applies to all zones and allows you select the pages you want to process.
Text Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted text to it and return the match.
Text Select:
Data Type = string
Use this to refine the text you extract more, select an option that matches your requirements
- text in zone: This option will select all the text that was extracted.
- word after value: If this option is selected, this action will return the word that appears immediately after the expression supplied below.
- word before value: If this option is selected, this action will return the word that appears immediately before the expression supplied below.
- all text in line after value: If this option is selected, this action will return all the words that appear on the same line after the expression supplied below.
- all text in line before value: If this option is selected, this action will return all the words that appear on the same line before the expression supplied below.
- all text in zone after value: If this option is selected, this action will return all the words that appear in the selected zone after the expression supplied below.
- all text in zone before value: If this option is selected, this action will return all the words that appear in the selected zone before the expression supplied below.
Text Value:
Data Type = string[]
Provide one or more value(s) here to be used with the property above, we will return the first text value that matches the rule stated above
Output Parameters
Text Result:
Data Type = string
A string generated from applying the extracted text to the file template provided.
Text Results:
Data Type = string
An array containing a list of pages and the extracted text values
Page Number:
Data Type = string
The page where the text was found
Page Text:
Data Type = string
A string generated from applying the extracted text to the Text Result Template provided.
Zone Values:
Data Type = string[]
An array containing the text extracted from each zone.
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Get barcode value
Extracts barcode from a PDF files in a smart way, the extracted information can be used to rename the file in Power Automate, it can also be used as an input to other processes. Properties like the location of the barcode on the page, the barcode format and regular expressions can be used to fine tune the result.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
Barcode Result Template:
Data Type = string
Template for the output text result if a barcode is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
%VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
%VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No Barcode Template:
Data Type = string
Template for the output text result if no barcode is found
Optional Parameters
Pages:
Data Type = string
Provide a page range you want to extract barcode values from, this can be a single page number (1), multiple page numbers separated by commas (1,2,3), a page range (1-4) or a mixture of all (1,2,4-7).
Page Separator:
Data Type = string
Provide a page separator so that you can know where the page breaks are.
Barcode Zones:
Data Type = Object []
A collection of variables that can be used to extract barcode information from PDF files, each member of this collection contains the properties listed below. Each member of this collection should produce a text output that corresponds to %VALUEn% of the Barcode Result Template discussed above.
Barcode Location:
Data Type = string
This represents the coordinates of a rectangle that covers the barcode you want us to extract. You can use this page to get the coordinates in relation to your input files.
Page (Deprecated):
Data Type = integer
This property is deprecated, we advise you to use the Pages property. The Pages property applies to all zones and allows you select the pages you want to process.
Barcode Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted barcode to it and return the match.
Barcode Type:
Data Type = string[]
Specify the types of Barcode you want to identify
"All 1D", "AZTEC", "CODABAR", "CODE 128", "CODE 39","CODE 93", "DATA MATRIX", "EAN 13", "EAN 8", "ITF","MAXICODE", "MSI", "PDF 417", "PLESSEY", "QR CODE","RSS 14", "RSS EXPANDED", "UPC A", "UPC E", "UPC EAN EXTENSION"
Output Parameters
Barcode:
Data Type = string
A string generated from applying the extracted text to the file template provided.
Barcode Results:
Data Type = string
An array containing a list of pages and the extracted barcode values
Page Number:
Data Type = string
The page where the barcode was found
Page Barcode:
Data Type = string
A string generated from applying the extracted barcode value to the Barcode Result Template provided.
Zone Values:
Data Type = string[]
An array containing the barcode extracted from each zone.
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Split PDF by barcode
Uses barcode values in PDF files to split the PDF file, you can also generate file names for the split files based on the barcode values.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
File Name Template:
Data Type = string
Template for the output text result if a barcode match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
%VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
%VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No Barcode Match Template:
Data Type = string
Template for the text to be returned if a barcode match is not found
Optional Parameters
Pages with no Match:
Data Type = string
Choose the location of the page with the barcode in the output files from the split operation.
Do not copy to output: If this option is selected, the pages without matches will not appear in the output.
Copy to output: If this option is selected, this action will also output the unmatched pages with the original file name
Copy to output and rename: If this option is selected, this action will also output the unmatched pages with the ‘No Text Match Template’ name
Output File Options:
Data Type = string
Depending on the split option you choose, some pages will have no barcode value extracted. Choose what to do with these pages.
- Barcode on first page: The barcode page will be the first page in the split section output.
- Barcode on last page: The barcode page will be the last page in the split section output.
- Remove barcode page: The barcode page will not appear in the split section output.
Barcode Zones:
Data Type = Object []
A collection of variables that can be used to extract barcode information from PDF files, each member of this collection contains the properties listed below. Each member of this collection should produce a text output that corresponds to %VALUEn% of the Barcode Result Template discussed above.
Barcode Location:
Data Type = string
This represents the coordinates of a rectangle that covers the barcode you want us to extract. You can use this page to get the coordinates in relation to your input files.
Barcode Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted barcode to it and return the match.
Barcode Type:
Data Type = string[]
Specify the types of Barcode you want to identify
"All 1D", "AZTEC", "CODABAR", "CODE 128", "CODE 39","CODE 93", "DATA MATRIX", "EAN 13", "EAN 8", "ITF","MAXICODE", "MSI", "PDF 417", "PLESSEY", "QR CODE","RSS 14", "RSS EXPANDED", "UPC A", "UPC E", "UPC EAN EXTENSION"
Output Parameters
Split Output Files:
Data Type = object[]
Array of Split Files with their corresponding file names.
File Content:
Data Type = string (byte – base 64 string)
A base 64 string representation of the spilt file.
File Name:
Data Type = string
File name for the split file above
Page Range:
Data Type = string
The page range containing the page numbers of the split operation
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Split PDF by text match
Uses text matches in PDF files to split the PDF file, you can also generate file names for the split files based on the barcode text matches.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
File Name Template:
Data Type = string
Template for the output text result if a text match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
%VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
%VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No File Template:
Data Type = string
Template for the text to be returned if a text match is not found
Optional Parameters
Pages with no Match:
Data Type = string
Choose the location of the page with the text match in the output files from the split operation.
Do not copy to output: If this option is selected, the pages without matches will not appear in the output.
Copy to output: If this option is selected, this action will also output the unmatched pages with the original file name
Copy to output and rename: If this option is selected, this action will also output the unmatched pages with the ‘No Text Match Template’ name
Output File Options:
Data Type = string
Depending on the split option you choose, some pages will have no text value extracted. Choose what to do with these pages.
Page that matches text on first page: The page with a text match will be the first page in the split section output.
Page that matches text on last page: The page with a text match will be the last page in the split section output.
Page that matches text The page with a text match will not appear in the split section output.
Text Zones:
Data Type = Object []
A collection of variables that can be used to extract text information from PDF files, each member of this collection contains the properties listed below. Each member of this collection should produce a text output that corresponds to %VALUEn% of the Text Result Template discussed above.
Text Location:
Data Type = string
This represents the coordinates of a rectangle that covers the text you want us to extract. You can use this page to get the coordinates in relation to your input files.
Text Page Number:
Data Type = integer
Provide a page number to extract text from, if empty we will try each page until we get a match.
Text Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted text to it and return the match.
Text Select:
Data Type = string
Use this to refine the text you extract more, select an option that matches your requirements
- text in zone: This option will select all the text that was extracted.
- word after value: If this option is selected, this action will return the word that appears immediately after the expression supplied below.
- word before value: If this option is selected, this action will return the word that appears immediately before the expression supplied below.
- all text in line after value: If this option is selected, this action will return all the words that appear on the same line after the expression supplied below.
- all text in line before value: If this option is selected, this action will return all the words that appear on the same line before the expression supplied below.
- all text in zone after value: If this option is selected, this action will return all the words that appear in the selected zone after the expression supplied below.
- all text in zone before value: If this option is selected, this action will return all the words that appear in the selected zone before the expression supplied below.
Text Value:
Data Type = string[]
Provide one or more value(s) here to be used with the property above, we will return the first text value that matches the rule stated above.
Output Parameters
Split Output Files:
Data Type = object[]
Array of Split Files with their corresponding file names.
File Content:
Data Type = string (byte – base 64 string)
A base 64 string representation of the spilt file.
File Name:
Data Type = string
File name for the split file above
Page Range:
Data Type = string
The page range containing the page numbers of the split operation
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Split PDF by page
Splits the PDF file using any of 4 different splitting options:
Split into single pages, Split by page range, Split by repeating range, Split by top level bookmarks.
Input Parameters
Required Parameters
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
Output File Name:
Data Type = string
The naming template for the output file name. Any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
- %FILENAME or %F%:The original file name without the .pdf extension.
- %UNIQUE or %U%:A unique identifier based on the start page number of the split file.
- %UNIQUE2, …, %UNIQUEn:A unique identifier based on the start page number of the split file. This identifier is restricted to ‘n’ significant figures (up to n = 6), and will add leading 0’s if needed.
- %TIMESTAMP:The current Time.
- %DATESTAMP:The current Date.
- %GUID:Generates a random string of numbers as a Globally Unique Identifier.
- %BOOKMARK:For use with ‘Split by top level bookmark’. The name of bookmark section of the split file.
File Name:
Data Type = string
The name of the source file.
Split Type:
Data Type = string
The split operation to be carried out on each file
- Split into single pages – gives a single page output for every page
- Split by page range – splits the document at the given page range
- Split by repeating range – splits the document at the given page range, repeating this split at each increment of ‘repeat Every’
- Split by top level bookmarks – splits at each top level bookmark found in the document
Optional Parameters
Page Range:
Data Type = string
Set of page ranges separated by commas that define which pages from the original should be extracted. The following types of page ranges are allowed:
- 1 – Specifies a single page
- 1-10 – Specifies a range of pages
- 1-lastpage – Specifies a range of pages, between 1 and the last page of the document
- 1-10odd – Specifies a range of pages, but only odd numbered pages will appear in the output
- 1-10even – Specifies a range of pages, but only even numbered pages will appear in the output
Repeat Every (Pages):
Data Type = int
Apply the Page Range to each set of page ranges within the document. For example, if 2-4 is specified for page ranges, and 4 is specified as the repeating range (Repeat Every), then the range is re-applied every 4 pages. Hence the file is split such that the first output file contains pages 2-4 from the original document; the second contains pages 6-8 and so on. Only work with a page range (1-3) and not single pages (1) or sets of ranges (1-3, 1).
Retain Bookmarks:
Data Type = boolean
Generated files will include bookmarks from the original file.
Retain Metadata:
Data Type = boolean
Generated files will include metadata (such as Author and Title) from the original file.
Output Parameters
Split Output Files:
Data Type = object[]
Array of Split Files with their corresponding file names.
File Content:
Data Type = string (byte – base 64 string)
A base 64 string representation of the spilt file.
File Name:
Data Type = string
File name for the split file above, without the file extension.
Page Range:
Data Type = string
The page range containing the page numbers of the split operation.
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Extract pages by barcode
Uses barcode values in PDF files to extract pages from the PDF file, you can also generate file names for the extracted files based on the barcode values.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
File Name Template:
Data Type = string
Template for the output text result if a text match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
- %VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
- %VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No File Template:
Data Type = string
Template for the text to be returned if a text match is not found
Optional Parameters
Barcode Zones:
Data Type = Object []
A collection of variables that can be used to extract barcode information from PDF files, each member of this collection contains the properties listed below. Each member of this collection should produce a text output that corresponds to %VALUEn% of the Barcode Result Template discussed above.
Barcode Location:
Data Type = string
This represents the coordinates of a rectangle that covers the barcode you want us to extract. You can use this page to get the coordinates in relation to your input files.
Barcode Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted barcode to it and return the match.
Barcode Type:
Data Type = string[]
Specify the types of Barcode you want to identify
"All 1D", "AZTEC", "CODABAR", "CODE 128", "CODE 39","CODE 93", "DATA MATRIX", "EAN 13", "EAN 8", "ITF","MAXICODE", "MSI", "PDF 417", "PLESSEY", "QR CODE","RSS 14", "RSS EXPANDED", "UPC A", "UPC E", "UPC EAN EXTENSION"
Output Parameters
Extracted Output Files:
Data Type = object[]
Array of Extracted Files with their corresponding file names.
File Content:
Data Type = string (byte – base 64 string)
A base 64 string representation of the spilt file.
File Name:
Data Type = string
File name for the extracted file above
Page Number:
Data Type = string
The page range containing the page number where the extraction occurred
Is Successful:
Data Type = boolean
This will return true if at least one page was extracted
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
Extract pages by text
Uses text matches in PDF files to extract pages from the PDF file, you can also generate file names for the split files based on the barcode text matches.
Input Parameters
Required Parameters
File Name:
Data Type = string
The name of the source file, this will be used for the file name template.
File Content:
Data Type = string (byte – base 64 string)
The content of the source file, this should be converted to a base64 string if you are passing it from code, otherwise Power Automate handles this aspect.
File Name Template:
Data Type = string
Template for the output text result if a text match is found, any occurrence of variables in the list below will be replaced by the appropriate value at runtime.
- %VALUE1%:The text extracted from the first zone that was extracted, if no zone was provided all the text in the page will be returned.
- %VALUE2%, …, %VALUEn%The text extracted from the nth zone that was extracted.
No File Template:
Data Type = string
Template for the text to be returned if a text match is not found
Optional Parameters
Text Zones:
Data Type = Object []
A collection of variables that can be used to extract text information from PDF files, each member of this collection contains the properties listed below. Each member of this collection should produce a text output that corresponds to %VALUEn% of the Text Result Template discussed above.
Text Location:
Data Type = string
This represents the coordinates of a rectangle that covers the text you want us to extract. You can use this page to get the coordinates in relation to your input files.
Text Page Number:
Data Type = integer
Provide a page number to extract text from, if empty we will try each page until we get a match.
Text Pattern:
Data Type = string
If a regular expression is provided here, we will match any extracted text to it and return the match.
Text Select:
Data Type = string
Use this to refine the text you extract more, select an option that matches your requirements
- text in zone: This option will select all the text that was extracted.
- word after value: If this option is selected, this action will return the word that appears immediately after the expression supplied below.
- word before value: If this option is selected, this action will return the word that appears immediately before the expression supplied below.
- all text in line after value: If this option is selected, this action will return all the words that appear on the same line after the expression supplied below.
- all text in line before value: If this option is selected, this action will return all the words that appear on the same line before the expression supplied below.
- all text in zone after value: If this option is selected, this action will return all the words that appear in the selected zone after the expression supplied below.
- all text in zone before value: If this option is selected, this action will return all the words that appear in the selected zone before the expression supplied below.
Text Value:
Data Type = string[]
Provide one or more value(s) here to be used with the property above, we will return the first text value that matches the rule stated above.
Output Parameters
Extracted Output Files:
Data Type = object[]
Array of Extracted Files with their corresponding file names.
File Content:
Data Type = string (byte – base 64 string)
A base 64 string representation of the spilt file.
File Name:
Data Type = string
File name for the extracted file above
Page Number:
Data Type = string
The page range containing the page number where the extraction occurred
Is Successful:
Data Type = boolean
A boolean value specifying if the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Error:
Data Type = string
Contains the Error message returned by the operation if any exist.
OCR PDF or images
Generate searchable PDF from an image PDF or scanned images.
Input Parameters
Required Parameters
Source file content:
Data Type = string (byte – base 64 string)
Content of the file to OCR
Source file name with extension:
Data Type = string (byte – base 64 string)
The source file name with extension or just the extension (with a leading period ‘.’)
Optional Parameters
Password:
Data Type = string
The password to open the source PDF file
Language:
Data Type = string
Selecting one of the option below sets the language to be used for the OCR processing. The default language is English.
"English"
"German"
"French"
"Russian"
"Swedish"
"Spanish"
"Italian"
"Russian_English"
"Ukrainian"
"Serbian"
"Croatian"
"Polish"
"Danish"
"Portuguese"
"Dutch"
"Czech"
"Romanian"
"Hungarian"
"Bulgarian"
"Slovenian"
"Latvian"
"Lithuanian"
"Estonian"
"Turkish"
Auto-rotate:
Data Type = boolean
Auto rotate the image – this will ensure all text oriented normally
Binarize:
Data Type = integer
This value should generally only be used under guidance from technical support. It can control the way that color images are processed and force binarization with a particular threshold. A value of 200 has been shown to generally give good results in testing, but this should be confirmed with “typical” customer documents. By setting this to -1 an alternative method is used which will attempt to separate the text from any background images or colors. This can give improved OCR results for certain documents such as newspaper and magazine pages.
Black pixel limit:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Blank page threshold:
Data Type = integer
Use this to set the minimum number of “On Pixels” that must be present in the image for a page not to be considered blank. A value of -1 will turn off blank page detection.
Box size:
Data Type = integer
This option is ideal for forms where sometimes boxes around text can cause an area to be identified as graphics. This option removes boxes from the temporary copy of the imaged used by the OCR engine. It does not remove boxes from the final image. Technically, this option removes connected elements with a minimum area (in pixels and defined by this property). This option is currently only applied for bi-tonal images.
Deskew:
Data Type = boolean
Deskew (straighten) the image.
Despeckle:
Data Type = integer
This removes all disconnected elements within the image that have height or width in pixels less than the specified figure. The maximum value is 9 and the default value is 0.
Grayscale quality:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Jbig2EncFlags:
Data Type = string
These are the flags that will be passed to the application used to generate JBIG2 versions of images used in PDF generation (assuming this compression is enabled). This option should generally only be used under guidance from technical support.
LibTiffSavePageAsBmp:
Data Type = boolean
Sometimes if there is an image which is 1bpp and has LZW compression, the pre-processing can cause the color of the image to be inverted (black to white and white to black). Set this to true to avoid this.
Maximum deskew:
Data Type = float
Maximum angle by which a page will be deskewed. This option should generally only be used under guidance from technical support (support@aquaforest.com).
Minimum deskew confidence:
Data Type = string
This option should generally only be used under guidance from technical support (support@aquaforest.com).
Morph:
Data Type = string
Morphological options that will be applied to the binarized image before OCR. If set to empty none is applied. Common options include those listed below but for more options please contact support@aquaforest.com:
Possible values
d2.2: 2x2 dilation applied to all black pixel areas, useful for faint prints.
e2.2: 2x2 erosion applied to all black pixel areas, useful for heavy prints.
c2.2: closing process that performs a 2x2 dilation followed by a 2x2 erosion with the result that holes and gaps in the characters are filled.
Contact technical support (support@aquaforest.com) for guidance on using this property.
Remove Blank Pages:
Data Type = boolean
Remove blank pages when BlankPageThreshold is greater than -1 and ConvertToTiff is true.
Remove Lines:
Data Type = boolean
Remove lines from images for better recognition.
Save Pre-despeckle:
Data Type = boolean
This will use the original image (i.e. before applying pre-processing) in the output PDF.
Compress PDF (MRC):
Data Type = boolean
This enables Mixed Raster Compression which can dramatically reduce the output size of PDFs comprising color scans. Note that this option is only suitable when the source is not a PDF or using ConvertToTiff.
Mrc Background Factor:
Data Type = integer
Sampling size for the background portion of the image. The higher the number, the larger the size of the image blocks used for averaging which will result in a reduction in size but also quality. Default value is 3
Mrc Foreground Factor:
Data Type = integer
Sampling size for the foreground portion of the image. The higher the number, the larger the size of the image blocks used for averaging which will result in a reduction in size but also quality. Default value is 3
Mrc Quality:
Data Type = integer
JPEG quality setting (percentage value 1 – 100) for use in saving the background and foreground images. Default value is 75
Pdf To Image Bpp:
Data Type = string
The Bits Per Pixel to use for the rasterized PDF page when using engine 1. This only applies for documents that are processed using ConvertToTiff. The default value for this property is taken from the PDF page.
Possible values
"Bpp_1"
"Bpp_24"
Pdf To Image Compression:
Data Type = string
The compression to set to the images extracted or rasterized from each page of the source PDF file. These images are then OCRed to create the searchable PDF. The default value for this property is taken from each page in the source PDF file.
Possible values
"CCITT4"
"LZW"
PDF To Image DPI:
Data Type = string
The DPI to set to the images rasterized from each page of the source PDF file. These images are then OCRed to create the searchable PDF. The default value for this property is taken from each page in the source PDF file.
Possible values
"DPI_72"
"DPI_100"
"DPI_150"
"DPI_200"
"DPI_300"
"DPI_400"
"DPI_500"
"DPI_600"
Pdf To Image Force Vector Check:
Data Type = boolean
This setting is useful when dealing with documents that contains vector objects (e.g. CAD drawings). By default, pages that contain only vector objects are rasterized. Pages that do not have any images but contain vector objects as well as electronic text are skipped from rasterization. However, sometimes there can be a page that contains vector objects (CAD drawings) but its title may be in electronic text. To force rasterizing pages like these, set this property to true.
Pdf To Image Include Text:
Data Type = boolean
When set to False this will prevent the conversion of real text (i.e. electronically generated as opposed to text that is part of a scanned image) from being rendered in the page images extracted from the PDF. This is because the text is already searchable and so generally does not require OCR. The value can be set to True however if the OCR is required on this real text.
Pdf To Image Max Res:
Data Type = integer
The maximum resolution of the rasterized images. If the resolution retrieved from the PDF page is bigger than this value, it will be set to this value. The default value for this property is 600.
Pdf To Image Min Res:
Data Type = integer
The minimum resolution of the rasterized images. If the resolution retrieved from the PDF page is lower than this value, it will be set to this value. The default value for this property is 200.
No Pictures:
Data Type = boolean
By default, if an area of the document is identified as a graphic area then no OCR processing is run on that area. However, certain documents may include areas or boxes that are identified as “graphic” or “picture” areas but that actually do contain useful text. Setting NoPictures to True will cause it to ignore areas identified as pictures whilst setting it to False will force OCR of areas identified as pictures.
Tables:
Data Type = boolean
This option when set to true, tries to OCR within table cells.
Text Layer Filter Height:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Height Inverted:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Percentage:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Percentage Inverted:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Ratio:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Ratio Inverted:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Width:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Filter Width Inverted:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Text Layer Max Boxes:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Author:
Data Type = string
Set a custom Author in the output PDF document properties.
Creation Date:
Data Type = string
Set a custom creation date in the output PDF document properties. The date string must be in the format ‘yyyy-MM-dd HH:mm:ss’.
Modified Date:
Data Type = string
Set a custom modified date in the output PDF document properties. The date string must be in the format ‘yyyy-MM-dd HH:mm:ss’.
Retain creation date:
Data Type = boolean
Retains the creation date of the source file in the output PDF document properties.
Retain modified date:
Data Type = boolean
Retains the modified date of the source file in the output PDF document properties.
Retain bookmarks:
Data Type = boolean
Retains any bookmarks from the source file in the output when using ConvertToTiff.
Retain metadata:
Data Type = boolean
Retains any metadata from the source file in the output when using ConvertToTiff.
Retain viewer preferences:
Data Type = boolean
Retains any PDF Viewer Preferences, Page Mode and Page Layout from source file in the output when using ConvertToTiff.
Dotmatrix:
Data Type = boolean
Set this to true to improve recognition of dot-matrix fonts. Default value is false. If set to true for non dot-matrix fonts then the recognition can be poor.
Enable debug output:
Data Type = boolean
Enables debug output.
PDF/A Output:
Data Type = boolean
Whether or not to output as PDF/A.
PDF/A Version:
Data Type = string
The PDF/A version.
Possible values
"PDF_A1b"
"PDF_A2b"
"PDF_A3b"
Validate PDF/A:
Data Type = boolean
Whether or not to validate the PDF/A document after conversion
Convert To Tiff:
Data Type = boolean
Each page in the PDF document is rasterized to a TIFF image.
Create Process:
Data Type = boolean
Set this to true if you want to launch process through pinvoke.
Error mode:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Restart Engine Every:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Tidy-up mode:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Dictionary Lookup:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Flip detect:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Heuristics:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Word match threshold:
Data Type = float
Contact technical support (support@aquaforest.com) for guidance on using this property.
Aquaforest Image Timeout:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
MRC Timeout:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
OCR Timeout:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Ocr Process Setup Timeout:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Pipe Client Connection Timeout:
Data Type = integer
Contact technical support (support@aquaforest.com) for guidance on using this property.
Output Parameters
Processed file content:
Data Type = string (byte – base 64 string)
PDF File generated by the Aquaforest PDF converter.
Log file content:
Data Type = string
The log contents of the operation.
Error message:
Data Type = string
Error message
Is Successful:
Data Type = boolean
Whether the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate
Get PDF properties
Gets the information about a PDF file.
Input Parameters
Required Parameters
File Content:
Data Type = string (byte – base 64 string)
Content of the file to OCR
Optional Parameters
Page Limit:
Data Type = integer
Maximum number of pages to be processed
Output Parameters
Allow Assembly:
Data Type = boolean
PDF Security setting that specifies if the document allows the rotation, insertion or deletion of pages.
Allow Degraded Printing:
Data Type = boolean
PDF Security setting that specifies if the document allows low-quality printing.
Allow Extract Contents:
Data Type = boolean
PDF Security setting that specifies if the document allows extraction of text and graphics.
Allow Extract For Accessibility:
Data Type = boolean
PDF Security setting that specifies if the document allows extraction of text and graphics in support of accessibility.
Allow Fill In Form:
Data Type = boolean
PDF Security setting that specifies if the document allows the filling of form fields.
Allow Modify Annotations:
Data Type = boolean
PDF Security setting that specifies if the document allows the modification of annotations
Allow Modify Contents:
Data Type = boolean
PDF Security setting that specifies if the document allows the rotation, insertion or deletion of pages.
Allow Printing:
Data Type = boolean
PDF Security setting that specifies if the document allows the high-quality printing.
Author:
Data Type = string
Who created the document.
Creation Date:
Data Type = string
This is the date and time the PDF was created.
Creator:
Data Type = string
The originating application or library.
File Size (bytes):
Data Type = string
The size of the file in bytes.
Has Hidden Text:
Data Type = boolean
This will return true if the PDF file has an OCR layer.
Is Searchable:
Data Type = boolean
This will return true if the PDF file is searchable.
Keywords:
Data Type = string
Keywords can be comma separated.
Modified Date:
Data Type = string
This property represents the date and time the PDF was last modified.
Number of Pages:
Data Type = integer
The number of pages in the PDF file.
PDF Version:
Data Type = number
The version of the PDF specification the document was built against.
Producer:
Data Type = string
The product that created the PDF. In the early days of PDF people would use a Creator application like Microsoft Word to write a document, print it to a PostScript file and then the Producer would be Acrobat Distiller, the application that converted the PostScript file to a PDF. Nowadays Creator and Producer are often the same or one field is left blank.
Subject:
Data Type = string
What is the document about.
Title:
Data Type = string
The title of the document.
Trapped:
Data Type = string
This property is a Boolean value that indicates whether the document has been trapped. Trapping is a pre-press process which introduces color areas into color separations in order to obscure potential register errors.
Xmp Metadata:
Data Type = string (XML)
The Extensible Metadata Platform (XMP) is an ISO standard, originally created by Adobe Systems Inc., for the creation, processing and interchange of standardized and custom metadata for digital documents and data sets.
Error message:
Data Type = string
Error message
Is Successful:
Data Type = boolean
Whether the operation was successful or not.
License Info:
Data Type = string
Information about your API subscription key, it contains:
LicenseType
CallsRemaining
CallsMade
RenewalDate